
펜윅 트리(Fenwick Tree, Binary Indexed Tree, BIT)
펜윅 트리(Fenwick Tree)는 세그먼트 트리의 변형으로 수열의 구간 합을 빠르게 구할 수 있도록 고안된 자료 구조입니다.
펜윅 트리는 Binary Indexed Tree라고도 하며, 줄여서 BIT라고 합니다.
펜윅 트리는 세그먼트 트리처럼 O(logN) 시간으로 구간 합을 구할 수 있으며 세그먼트 트리에 비해 적은 공간이 필요하고 구현하기 쉽다는 장점이 있습니다.
펜윅 트리 구성
배열 A를 가지고 세그먼트 트리를 만들면 다음과 같습니다. 각 노드에는 구간합 정보가 들어 있습니다.
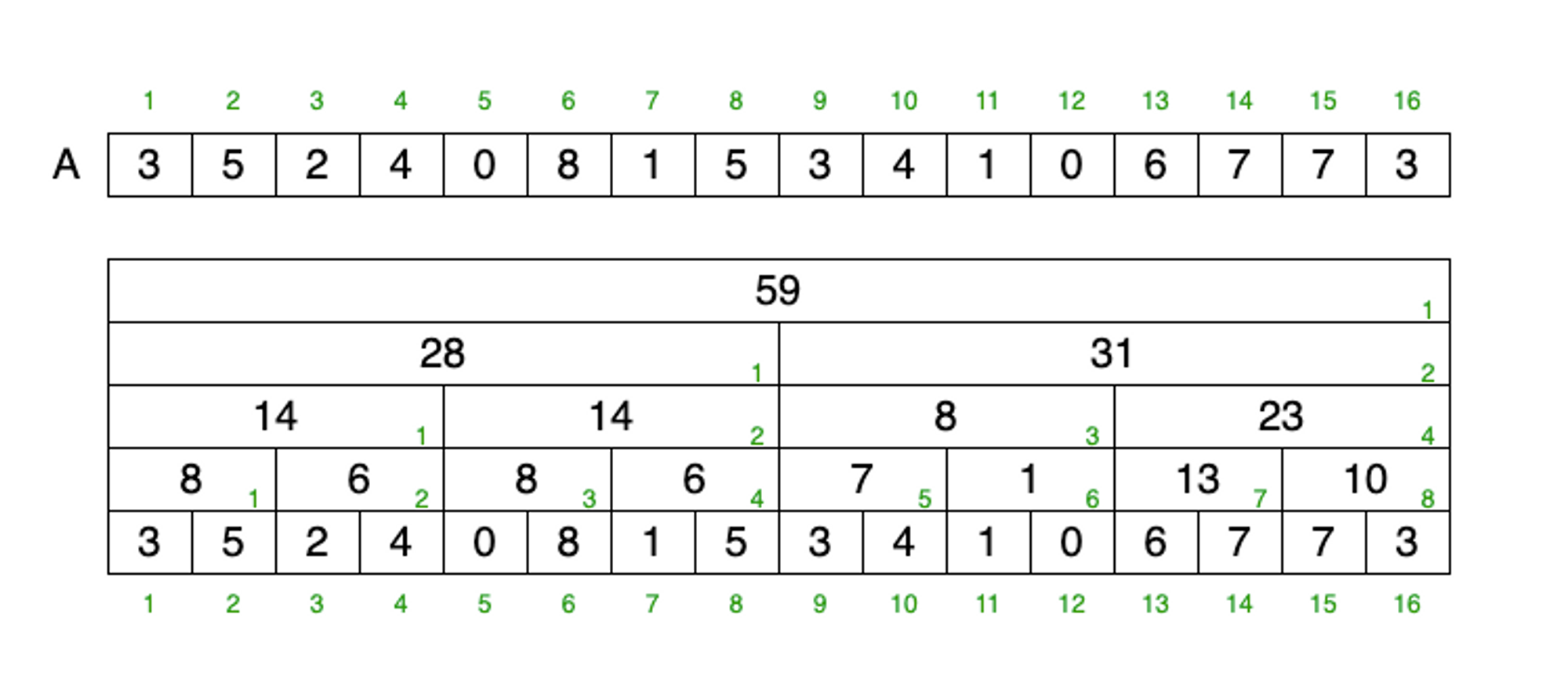
위 세그먼트 트리에서 각 층에에서 짝수 인덱스를 무시하면 아래와 트리를 얻을 수 있습니다.
이러한 구조를 펜윅 트리라고 합니다.
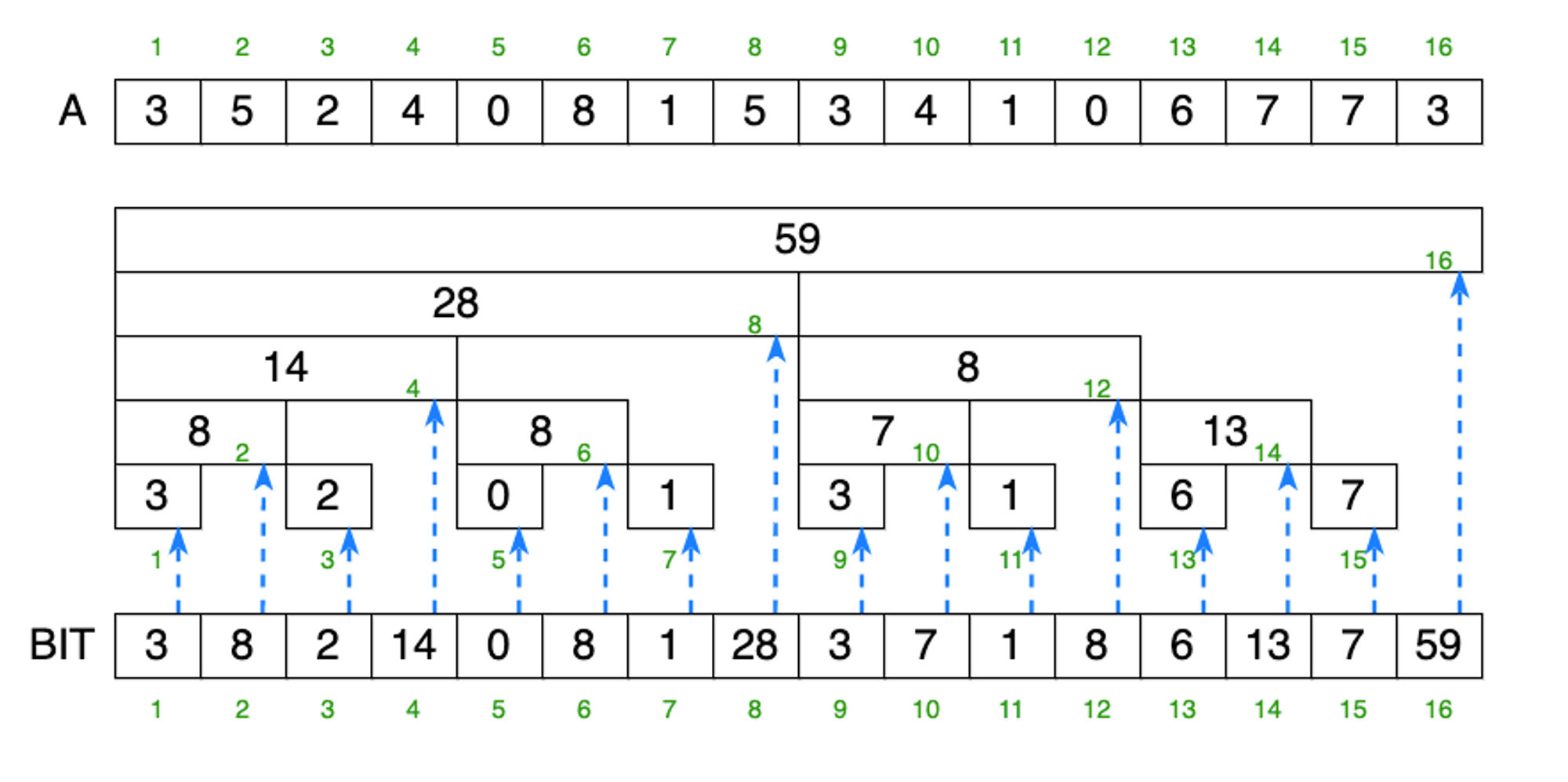
주어진 n개의 배열을 가지고 세그먼트 트리를 만들려면 2n-1만큼의 배열이 필요하지만 펜윅트리는 n개의 배열만으로 구현이 가능합니다.
펜윅 트리의 홀수 번째 인덱스는 리프 노드로써 배열 값을 저장하고 있고, 짝수번째는 내부 노드로써 블록 구간만큼의 구간 합 정보가 저장되어 있습니다.
펜윅 트리 구현
비트 연산을 알고 있다면 구현이 쉬운 편입니다.
편의를 위해 1 기반 인덱싱을 사용합니다.
0이 아닌 최하위 비트
펜윅 트리를 구현하기 전 주어진 값에 0이 아닌 최하위 비트를 알아야 합니다.
다음은 주어진 수에 최하위 비트를 나타냅니다. 최하위 비트는 빨강으로 표시함.
3 = (11)₂
5 = (101)₂
6 = (110)₂
8 = (1000)₂
i 값에 최하위 비트는 i & -i이 됩니다.
다음은 i = 6 (110)₂에서 최하위 비트를 가져오는 과정입니다.
i = 110
~i = 001
-i = ~i + 1
= 001 + 1
= 010
i & -i = 110 & 010
= 010
이 최하위 비트를 가져오는 연산은 sum과 add연산에 사용됩니다.
Sum
인덱스 1부터 i까지 부분 합을 구하는 연산입니다.
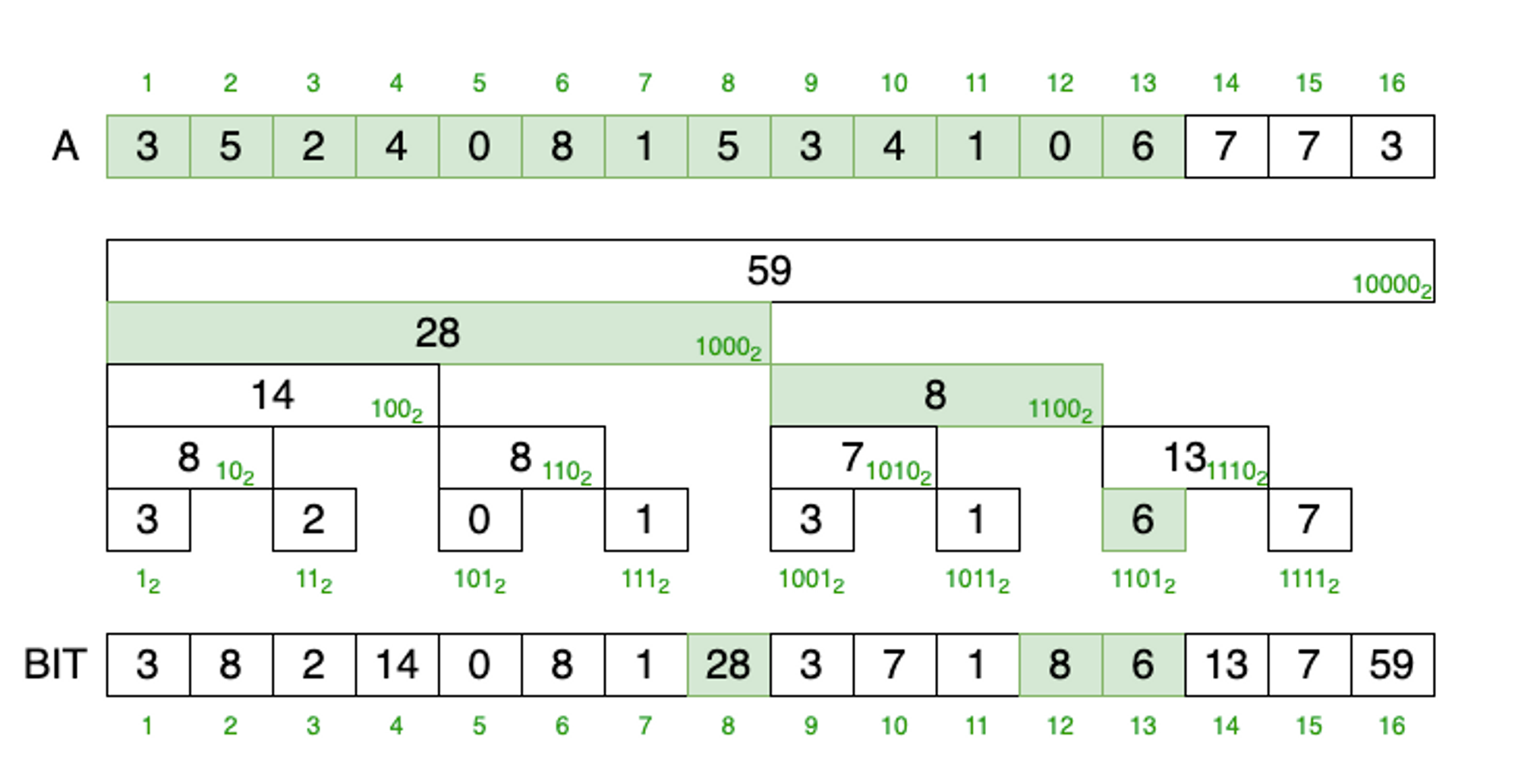
위 예에서는 1 ~ 13 까지 부분합을 구하기 위해 13 = (1101)₂, 12 = (1100)₂ 및 8= (1000)₂ 위치의 값을 합산하여 부분합을 구하게 됩니다.
- sum(13) = BIT[13] + BIT[12] + BIT[8] = 6 + 8 + 28 = 42
이 위치는 최하위 비트를 빼면서 찾을 수 있습니다.
def sum(i):
ret = 0
while i > 0:
ret += tree[i]
i -= (i & -i)
return retAdd
i번째 배열에 값을 추가하는 연산입니다.
이때 i번째 인덱스를 포함하는 모든 노드들도 업데이트합니다.
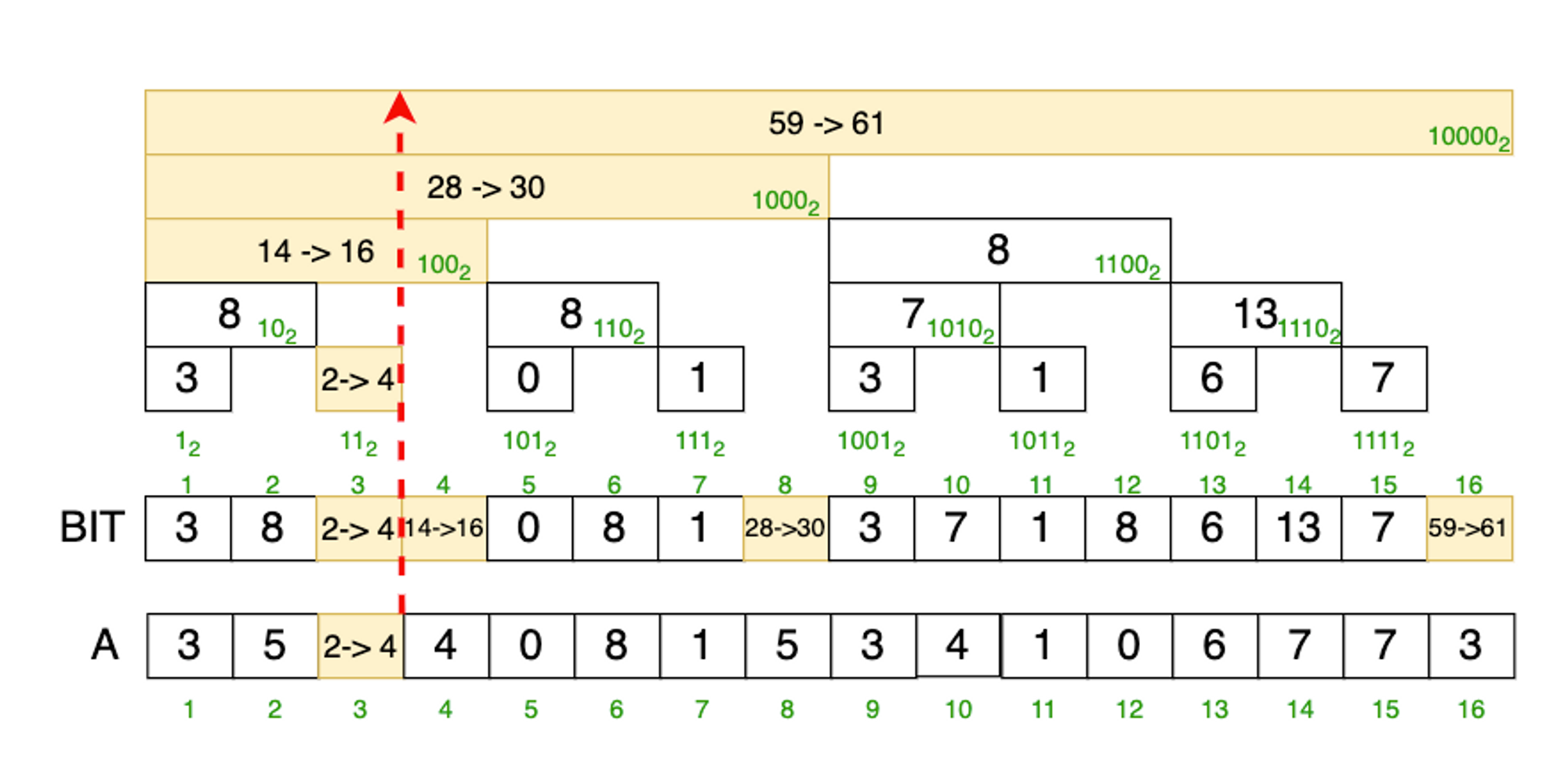
위 예는 A[3] += 2 연산을 하기 위해 BIT 배열에 3 = (11)₂, 4 = (100)₂, 8 = (1000)₂, 16 = (10000)₂ 위치에 값을 변경해 줍니다.
이 위치는 최하위 비트를 더하면서 찾을 수 있습니다.
def add(i, num):
while i <= n:
tree[i] += num
i += (i&-i)
sum, add 연산을 가지고 아래 연산을 구현할 수 있습니다.
- Point Update & Range Query
- Range Update & Point Query
- Range Update & Range Query
여기선 1, 2를 알아보도록 하겠습니다.
Point update & Range query
Point update
point update는 i 번째 배열 값을 x만큼 증가시키는 작업을 합니다
def update(i, x):
add(i, x)
Range query
range query는 구간합을 구하는 연산입니다.
펜윅 트리는 세그먼트 트리와 다르게 구간합 정보가 일부만 저장되어 있어 부분합 정보만 가져올 수 있습니다.
(여기서 i번째 인덱스에 대한 부분 합은 0~i 까지 합을 의미합니다.)
때문에 구간 합을 구하려면 추가 연산이 필요 합니다.
구간합 [l, r]을 구하기 위해 [0, r] 과 [0, l-1]의 부분합을 빼는 연산을 해야 합니다.

인덱스 L부터 R까지 구간 합을 구하는 연산입니다.
def range_query(l, r):
return sum(r) - sum(l-1)Range update & Point query
Range update
Range Update는 [l, r] 범위의 값을 x만큼 증가시키는 연산을 합니다.
[l, r] 범위의 값을 x만큼 증가시키는 범위 업데이트를 해주기 위해선 다음 두 가지 포인트 연산을 해주면 됩니다.
- add(l, x), add(r+1, -x)
def range_update(l, r, x):
add(l, x)
add(r+1, -x)다음 연산을 사용하여 point update도 가능합니다.
- range_update(i, i, val)
다음은 0으로 초기화된 A배열을 가지고 [4, 6] 범위의 값을 5만큼 증가시키는 예입니다.
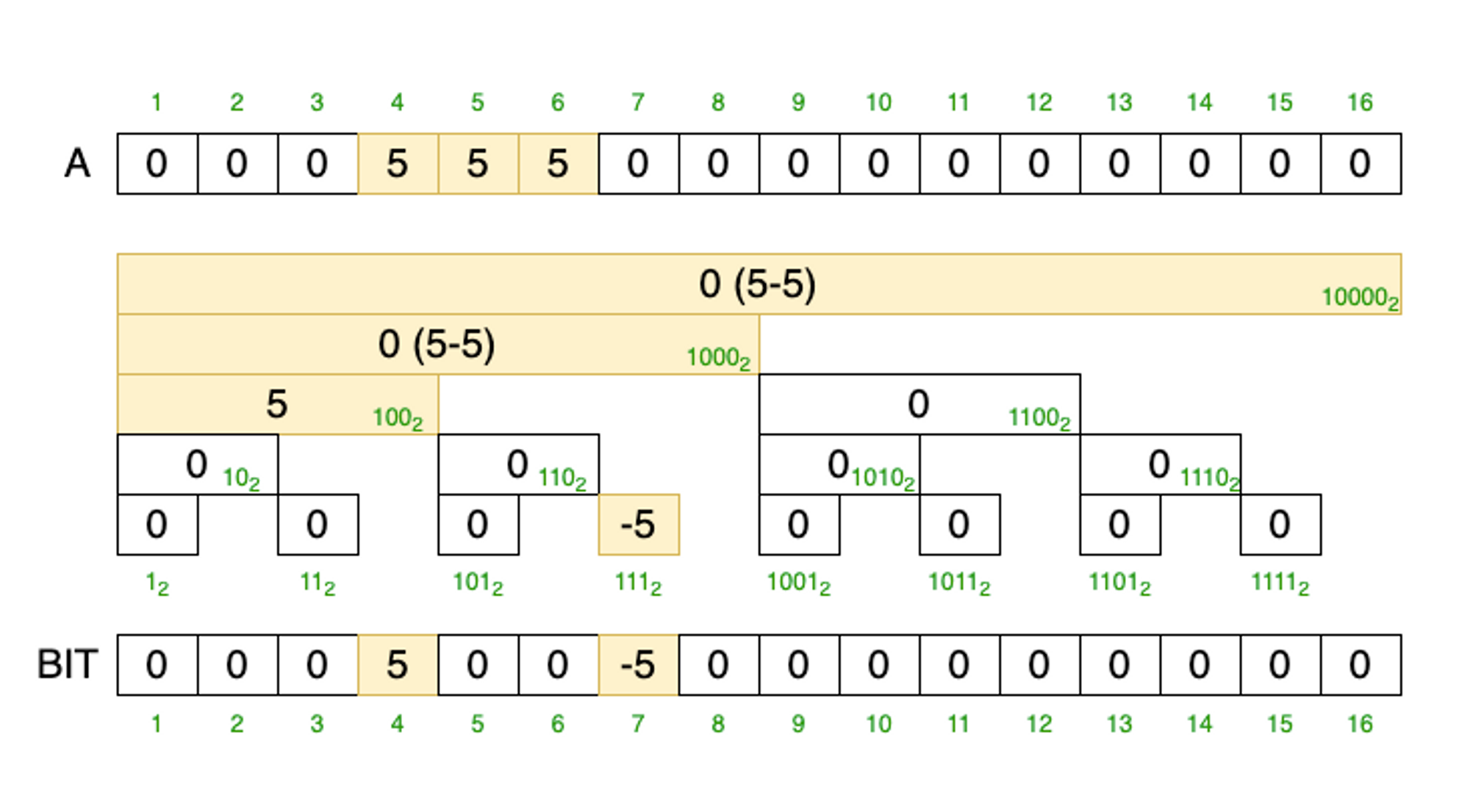
Point query
Point query는 Range update 이후 i번째 위치에 있는 값을 가져오는 연산을 합니다.
[l, r] 범위에 Range update 연산 이후 i 위치에 따라 다음 특성이 있습니다. (위 그림을 보면 이해하기 쉬움)
- i < l
- l 이전에는 증가 작업이 없었으므로 sum(i)의 결과는 0이 됩니다.
- l ≤ i ≤ r
- l 범위부터 x만큼 증가 작업이 있었으므로 sum(i)의 결과는 x가 됩니다.
- r < i
- r+1 부터 x만큼 감소 작업이 있었으므로 l범위부터 시작된 x만큼 증가되는 작업이 상쇄됩니다.
이런 특성이 있기 때문에 A[i] 값을 얻기 위해서는 다음 연산만 해주면 됩니다.
- sum(i)
def point_query(i):
return sum(i)



