
문자열 검색 알고리즘 : Boyer Moore - Good Suffix Heuristics 알아보기
Bad character heuristics은 한 칸만 이동하는 경우가 있습니다. 이 경우 최대 이동 거리를 도출하기 위한 방법으로 Good Suffix Heuristics를 사용합니다.
Good Suffix는 패턴의 문자 일부와 일치하는 텍스트의 부분 문자열을 말합니다.
Good Suffix Heuristics는 세 가지 상황이 있으며 각 상황에 맞는 오프셋을 제공합니다.
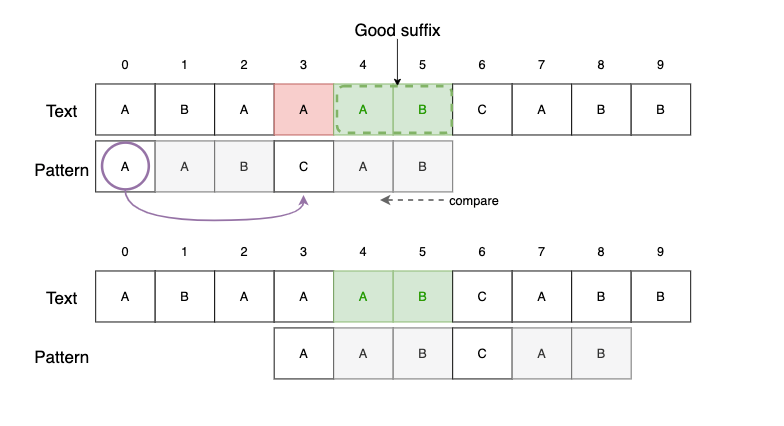
Case1. Good Suffix가 패턴의 다른 곳에도 있는 경우
- 다른 곳에 있는 일치하는 패턴 문자를 Good Suffix와 일치하도록 패턴을 이동시킵니다.
- 아래 그림에서 Bad character heuristics를 사용한다면 한칸만 이동하게 됩니다.
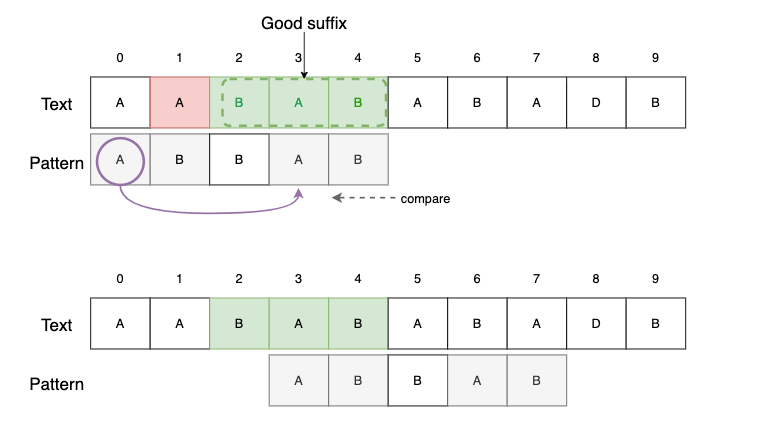
Case2. Good Suffix의 일부만 패턴의 시작 부분에 있는 경우
- 패턴의 접두사 부분을 Good Suffix 부분에 일치하도록 패턴을 이동시킵니다.
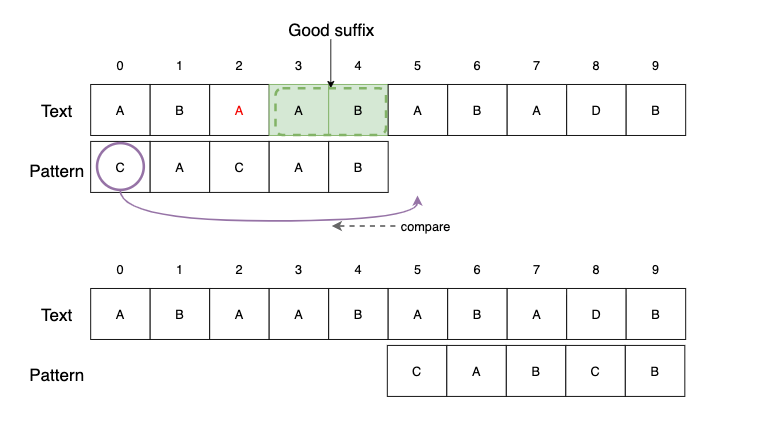
Case3. Good Suffix가 패턴의 다른 곳에 없는 경우
- 패턴을 Good Suffix 이후로 이동합니다.
전처리 (preprocessing)
Good Suffix 발생 시, 이동 위치를 저장하고 있는 shift[]배열을 만들기 위한 전처리 작업이 필요합니다.
이동 위치를 결정하기 위해서는 두 가지 경우가 있습니다.
Case1. Good Suffix가 패턴의 다른 곳에도 있는 경우
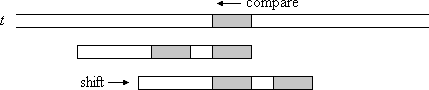
이 경우는 KMP 전처리 과정과 유사합니다. bpos는 경계 위치를 저장합니다. 경계(border)란 proper prefix와 proper suffix에 둘 다 가지고 있는 부분 문자열을 말합니다.
예를 들어 CCACC라는 문자열에 C와 CC는 양쪽 문자 끝에 있기 때문에 경계이지만 CCA는 경계가 아닙니다.
bpos[i]는 패턴의 i번째에서 시작하는 부분 문자열에 대한 경계 중 접미사에 있는 경계의 시작 인덱스를 저장합니다.
예를 들어 p =CCACC에서 bpos[1]은 4이고 bpos[0]은 3입니다.
i: 0 1 2 3 4 5
p: C C A C C
p[1]부터 시작하는 패턴의 부분문자열에서 경계는 p[1]과 p[4]이고 bpos[1]은 4이다.
i: 0 1 2 3 4 5
p: C C A C C
p[0]부터 시작하는 패턴의 부분 문자열(패턴 전체)에서 경계는 p[0..1]과 p[3..4]이다.
bpos는 접미사 부분에 대한 경계의 시작 인덱스를 포함하므로 bpos[0]은 3이다.
패턴의 접미사에 있는 경계를 찾아야 하기 때문에 뒤에서 부터 탐색을 시작합니다.
패턴의 길이가 m이라면 bpos[m]은 m+1입니다. 왜냐하면 m위치에는 경계가 없기 때문입니다.
예를 들어 패턴 p = CCACC를 bpos(=b)에 저장하면 다음과 같습니다.
i: 0 1 2 3 4 5 6
p: C C A C C
b: 3 4 5 4 5 6
이동 위치 s는 패턴이 불일치하는 경우 이동거리를 저장합니다.
P[i-1] ≠ p [j-1]일 때 패턴을 i에서 j로 옮겨야 하기 때문에 shift[j] = j-i 로 저장하고, j위치에서 불일치가 발생할 때마다 패턴을 shift[j+1] 위치만큼 오른쪽으로 이동시키게 됩니다.
동일한 경계를 갖는 접미사에 대해서 s값의 수정을 방지하기 위해 s 값이 0일때만 값을 수정해 줍니다.
CCACC에 대한 이동위치 s는 다음과 같습니다.
i: 0 1 2 3 4 5 6
p: C C A C C
b: 3 4 5 4 5 6
s: 0 0 0 0 1 2
위 전처리 과정을 코드로 나타내면 다음과 같습니다.
void preprocess_case1(int *shift, int *bpos,
char *pat, int m)
{
int i = m, j = m+1;
bpos[i] = j;
while(i > 0)
{
while(j <= m && pat[i-1] != pat[j-1])
{
if (shift[j] == 0)
shift[j] = j-i;
j = bpos[j];
}
i--; j--;
bpos[i] = j;
}
}case2. Good Suffix의 일부만 패턴의 시작 부분에 있는 경우
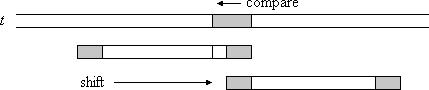
이 경우에서는 패턴의 일치하는 접미사의 일부가 패턴의 시작 부분에서 발생합니다. 이것은 이 부분이 패턴의 경계라는 것을 의미합니다.
패턴의 접미사 부분으로 패턴을 이동시켜야 하기 때문에 모든 s는 bpos[0]으로 초기화시킵니다.
하지만 패턴의 접미사가 bpos[0]보다 짧아지는 시점에서는 다음으로 넓은 경계인 bpos[bpos[0]]를 저장하고 이를 계속 반복합니다.
위 내용을 코드로 나타내면 다음과 같습니다.
void preprocess_case2(int *shift, int *bpos,
char *pat, int m)
{
int i, j;
j = bpos[0];
for(i=0; i<=m; i++)
{
if(shift[i]==0)
shift[i] = j;
if (i==j)
j = bpos[j];
}
}
다음은 case1, case2에 대한 전처리 이후 패턴 CCACC에 대한 최종 s 값입니다.
i: 0 1 2 3 4 5 6
p: C C A C C
b: 3 4 5 4 5 6
s: 3 3 3 3 1 2문자열 검색 단계
문자열 검색은 오른쪽에서 왼쪽으로 패턴과 비교합니다.
패턴을 찾았다면 패턴이 이동한 정보를 출력하고 텍스트에 남아있는 패턴을 찾기 위해 패턴을 이동시킵니다.
패턴을 찾지 못했다면 Good Suffix Heuristics에서 제공하는 오프셋만큼 패턴을 이동시킵니다.
void search(char *text, char *pat)
{
int m = strlen(pat);
int n = strlen(text);
int s=0; // 텍스트에 대한 패턴을 이동시키기 위한 변수
int bpos[m+1], shift[m+1];
for(int i=0;i<m+1;i++) shift[i]=0;
//전처리 단계
preprocess_case1(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
// 문자열 검색 단계
while(s <= n-m)
{
int j = m-1;
// 텍스트와 패턴을 오니쪽에서 오른쪽으로 비교
while(j >= 0 && pat[j] == text[s+j])
j--;
// 텍스트에서 패턴을 발견한 경우
if (j<0) {
printf("pattern occurs at shift = %d\n", s);
// 패턴을 다음 위치로 이동시킴
s += shift[0];
}
else {
// 패턴과 불일치하는 경우 오프셋만큼 패턴을 이동
s += shift[j+1];
}
}
}Input & Output
Input:
txt[] = "ABAAAABAACD"
pat[] = "ABA"
Output:
pattern occurs at shift = 0
pattern occurs at shift = 5마치며
boyer-moore 알고리즘은 두 가지 휴리스틱이 있습니다. (bad charater heuristics, good suffix heuristics)
이 규칙을 따로 사용하는 것이 아니라 불일치가 일어날 때마다 두 heuristics에서 제공하는 offset중 가장 큰 값을 이용하여 패턴을 이동시키게 됩니다.
하지만 Good Suffix heuristics는 다소 이해하고 구현하기 어렵기 때문에 bad charater heuristics만 이용하기도 합니다.



