
KMP(Knuth Morris Pratt) 알고리즘 알아보기
navie 알고리즘은 최악의 경우 O(m(n-m+1))의 시간이 걸립니다. (n 패턴의 길이, m 텍스트 길이)
문자 하나하나 씩 비교하기 때문에 불필요한 문자 비교가 있을 수 있습니다.
다음은 navie 알고리즘으로 텍스트 T[]="banananobano"에서 패턴 P[]="nano"를 찾는 과정입니다.

이 동작에서 일부는 낭비입니다. i=2에서 T[3] = 'a', T[4]='n' 이라는 것을 확인했으니 i=3, 4에서 패턴 n과 비교하는 것은 불필요합니다.
KMP 알고리즘은 lps(Longest Proper Prefix which is Suffix) 배열을 사용하여 문자열 검색 시 불필요한 문자 간 비교를 없애 성능을 개선시킨 알고리즘입니다.
lps[]란 일치하지 않는 문자가 있을 때 어디서부터 검색을 해야 할지(몇 칸을 뛰어넘어야 하는지) 알려주기 위한 지표 역할을 합니다.
전처리 단계에서 lps[]를 구성하는 작업을 합니다.
전처리(Preprocess) 단계
전처리 단계에서 패턴을 사용하여 lps[]를 구성합니다. (lps의 크기는 패턴 길이와 같습니다.)
lps는 문자열중 suffix와 동일한 가장 긴 proper prefix입니다. 여기서 proper prefix란 일반 prefix와 다르게 문자열 자기 자신은 제외됩니다.
예) 문자열 "ABC"
- prefix : "", "A", "AB", "ABC"
- proper prefix: "", "A", "AB"
문자열 "ACA"에서 lps를 구한다면 다음과 같습니다.
- proper prefix: "", "A", "AC"
- suffix: "", "A", "CA", "ACA"
이중 suffix와 동일한 가장 긴 proper prefix인 lps는 "A" 입니다.
lps 배열은 문자열 위치에 해당하는 하위 문자열의 lps 길이가 저장되어 있습니다.
lps 배열을 사용하면 문자열에서 이미 검사했던 문자들을 다시 검사하는 것을 피할 수 있습니다.
다음은 AABAAC 패턴에 대한 LPS배열의 단계별 구성 예입니다.
대시 막대는 현재 LPS 인덱스에 대해 고려되는 패턴의 하위 문자열을 보여줍니다. LPS는 초록색 블록으로 나타냅니다.
Step1.
하위 문자열 길이가 1인 경우 proper prefix는 없기 때문에 lps[0] 은 항상 0입니다.
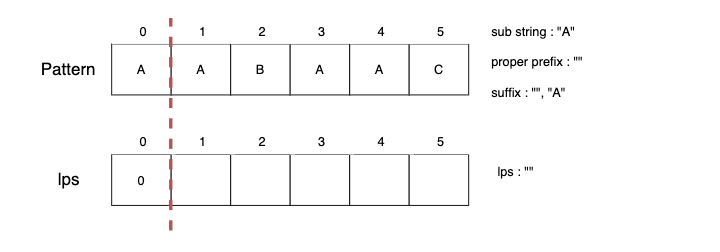
Step2.
하위 문자열 "AA"의 lps는 "A"이기 때문에 lps[1]=1을 저장합니다.
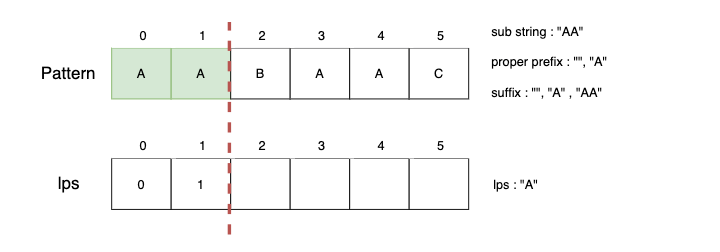
Step3.
하위 문자열 "AAB"의 lps는 없기 때문에 lps[2] = 0을 저장합니다.
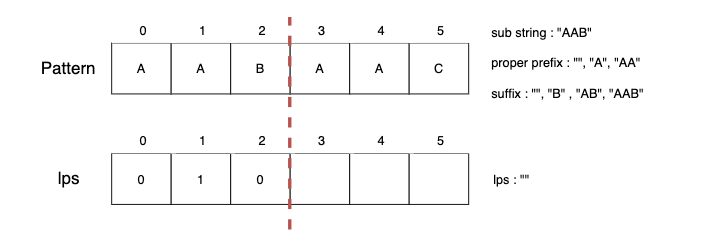
Step4.
하위 문자열 "AABA"의 lps는 "A"이기 때문에 lps[3] = 1을 저장합니다.
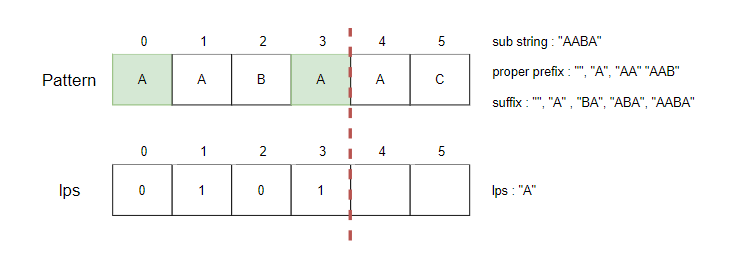
Step5.
하위 문자열 "AABAA"의 lps는 "AA"이기 때문에 lps[4] = 2를 저장합니다.
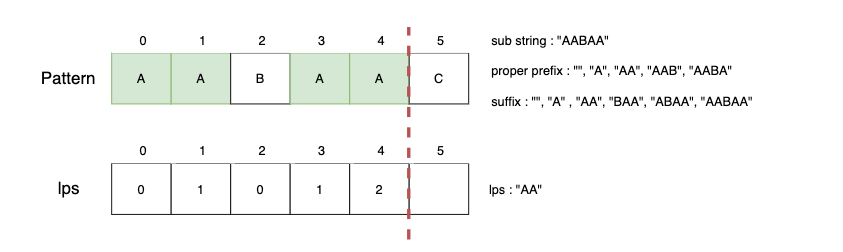
Step6.
하위 문자열 "AABAAC"의 lps는 없기 때문에 lps[5]=0을 저장합니다.
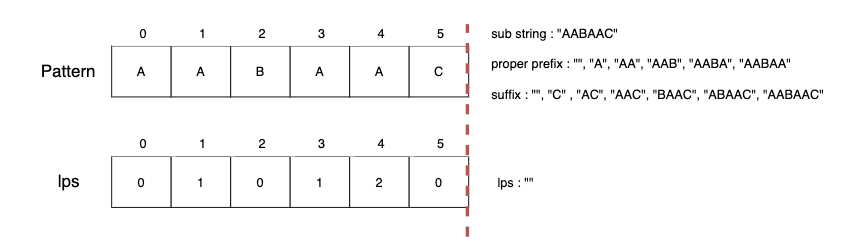
문자열 검색
kmp 알고리즘은 lsp[]를 사용하여 일치시킬 다음 문자를 결정합니다.
어떻게 lsp[] 사용하여 문자열을 검색하는지 알아보겠습니다.
mismatch인 경우 다음 두 가지 사실을 알고 있습니다.
- pattern[0...j-1]과 text[i-j ... i-1]가 같다.
- lps[j-1]에 pattern[0 ... j-1]의 suffix와 동일한 가장 긴 proper prefix의 길이가 저장되어 있다.
위 두 가지 사실로 lps[j-1]에 저장된 길이만큼의 pattern을 text[i-j...i-1]와 일치시킬 필요가 없다는 결론이 나옵니다.
다음 그림에서 i=7, j=5일 때 pat[5]와 txt[7]은 불일치합니다. 하지만 pat[0 ... 4] 와 txt[2 ... 6]은 같다는 것을 알 수 있습니다.
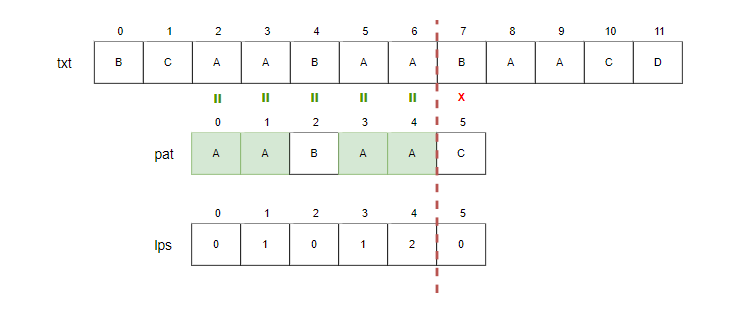
pat에 있는 하위 문자열("AABAA")에 대한 lps[4]에 길이 2만큼의 prefix("AA")가 suffix("AA")와 같다는 사실을 알고 있습니다.
그렇기 때문에 다음과 같이 lps[4]에 있는 위치 2부터 pat을 비교할 수 있게 됩니다.
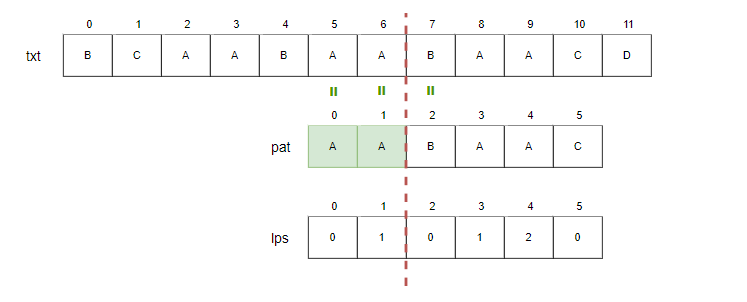
이 처럼 문자 하나하나씩 비교할 필요 없이 lps배열을 사용하면 비교 문자를 스킵할 수 있어 불필요한 문자 비교를 피할 수 있습니다.
구현
문자열 검색 단계
문자열 검색에는 match와 mismatch 두 가지 경우가 있습니다.
match (pat[i] == txt[i])
- text[i] 와 pattern[j]가 일치할 때마다 i와 j를 증가시킵니다.
- j == M인 경우 패턴을 찾은 위치(i-j)를 출력하고 j를 lps[j-1]에 저장된 값으로 초기화시킵니다.
mismatch (pat[i] != txt[j])
- j=0이 아니라면 j를 lps[j-1]에 저장된 값으로 설정합니다.
- j=0이라면 i를 증가시킵니다.
문자열 검색 단계는 text의 길이 N만큼 연산을 수행하기 때문에 O(N)이 소요됩니다.
구현하면 다음과 같습니다.
void KMP(char txt[], char pat[])
{
int N = strlen(txt); // 텍스트 길이
int M = strlen(pat); // 패턴 길이
int lps[M];
// 전처리 단계
computeLPSArray(pat, M, lps);
// 문자열 검색 단계
int i = 0; // 텍스트를 위한 index
int j = 0; // 패턴을 위한 index
while (i < N) {
if (pat[j] == txt[i]) // match
{
i++;
j++;
if (j == M) {
printf("Found pattern at index %d ", i - j);
j = lps[j - 1];
}
}
else // mismatch (pat[j] != txt[i])
{
if (j != 0)
j = lps[j - 1];
else
i++;
}
}
}Input & Output
Input:
txt[] = "BCAABAABAACD"
pat[] = "AABAAC"
Output:
Found pattern at index 5그림 예시
다음은 KMP알고리즘을 사용하여 문자열 txt[N] = BCAABAABAACD에서 패턴 pat[M] = AABAAC를 찾는 과정입니다.
(i는 txt의 인덱스이고 j는 pat의 인덱스입니다.)
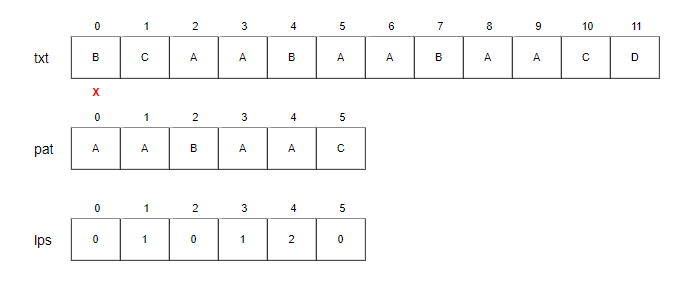
Step1.
- i=0, j=0.
- txt[0]와 pat[0]을 비교합니다. 불일치하므로 i를 증가시킵니다.
Step2.
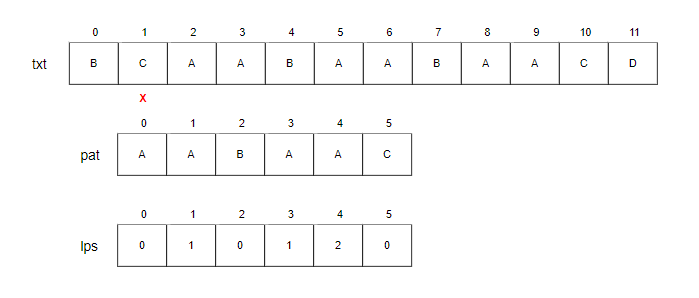
- i=1, j=0.
- txt[1]과 pat[0]을 비교합니다. 불일치하므로 i를 증가시킵니다.
Step3.
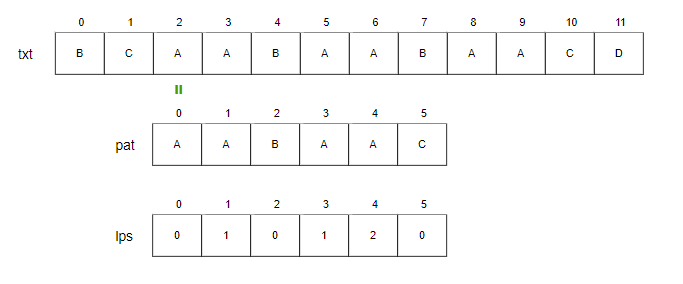
- i=2, j=0.
- txt[2]와 pat[0]을 비교합니다. 일치하므로 i와 j를 증가시킵니다.
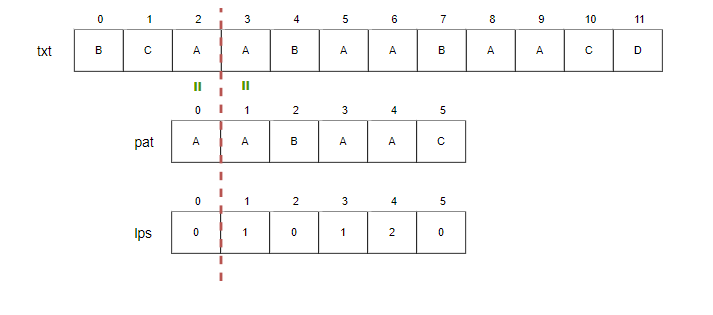
Step4.
- i=3, j=1.
- txt[3]와 pat[1]을 비교합니다. 일치하므로 i와 j를 증가시킵니다.
Step5.
- i=4, j=2.
- txt[4]와 pat[2]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
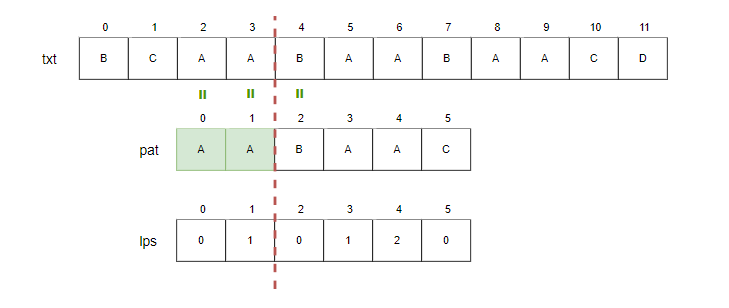
Step6.
- i=5, j=3.
- txt[5]와 pat[3]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
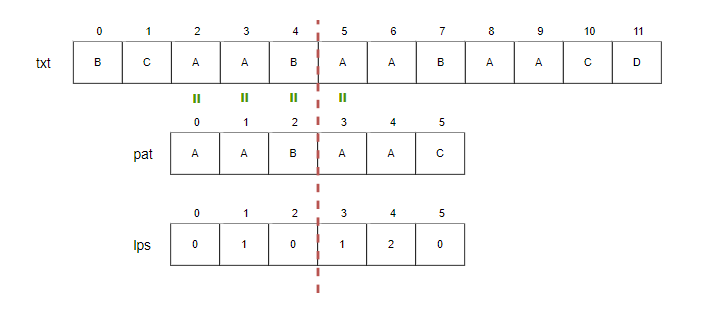
Step7.
- i=6, j=4.
- txt[6]와 pat[4]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
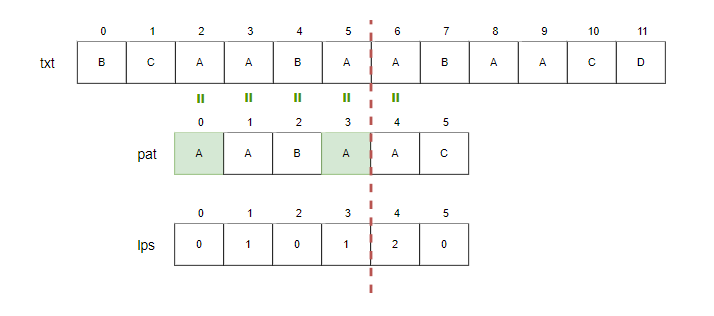
Step8.
- i=7, j=5.
- txt[7]과 pat[5]를 비교합니다. 불일치하므로 불필요한 비교를 줄이기 위해 lps[j-1] 값을 참조하여 j를 설정합니다. j-1에 있는 lps를 참조하기 때문에 j > 0인 경우에만 참조할 수 있도록 합니다.
- j= lps[j-1] = lps[4] = 2
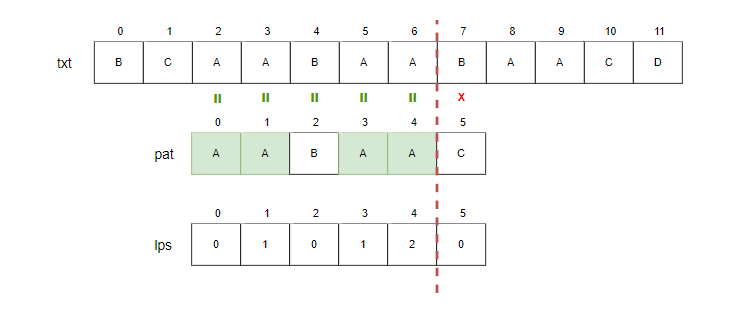
Step9.
- i=7, j=2.
- txt[7]과 pat[2]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
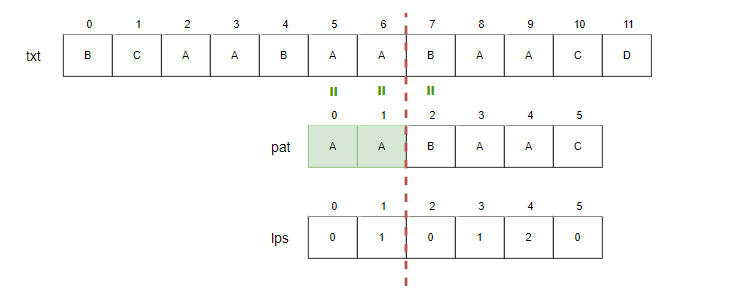
Step10.
- i=8, j=3.
- txt[8]과 pat[3]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
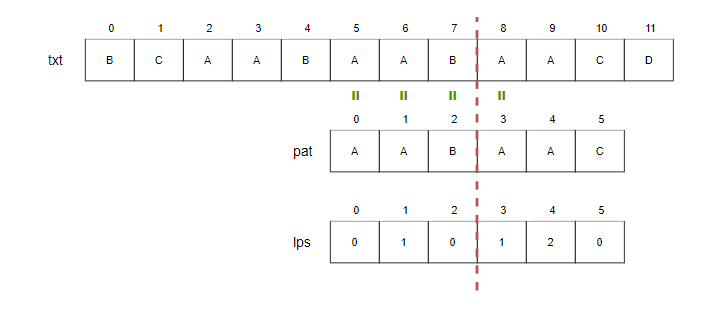
Step11.
- i=9, j=4.
- txt[9]과 pat[4]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
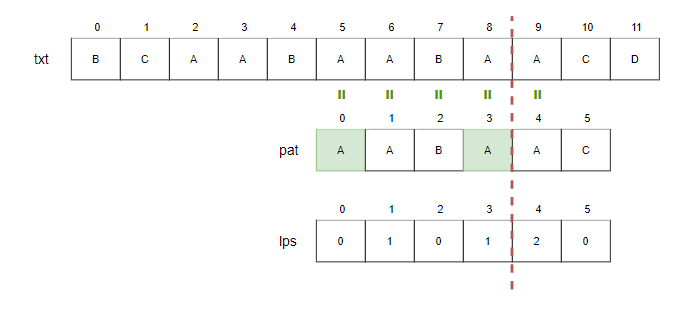
Step12.
- i=10, j=5.
- txt[10]과 pat[5]를 비교합니다. 일치하므로 i와 j를 증가시킵니다.
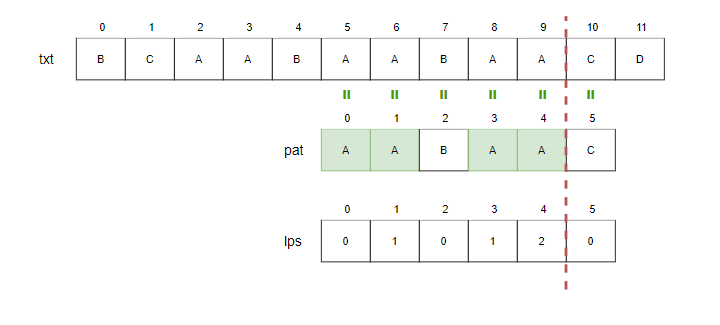
Step13.
- i=11, j=6.
- j == M 이므로 패턴을 찾은 위치(i-j)를 출력합니다. j > 0이므로 lps 배열을 참조합니다.
- j=lps[j-1]=lps[5]=0.
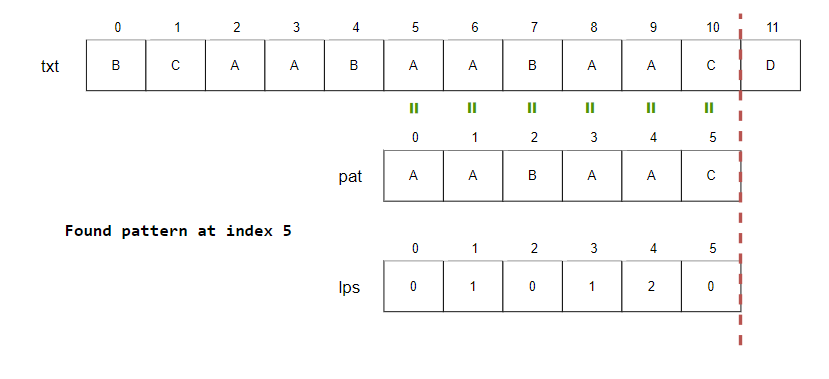
Step14.
- i=11, j=0.
- txt[11]과 pat[0]을 비교합니다. 불일치하므로 i를 증가시킵니다.
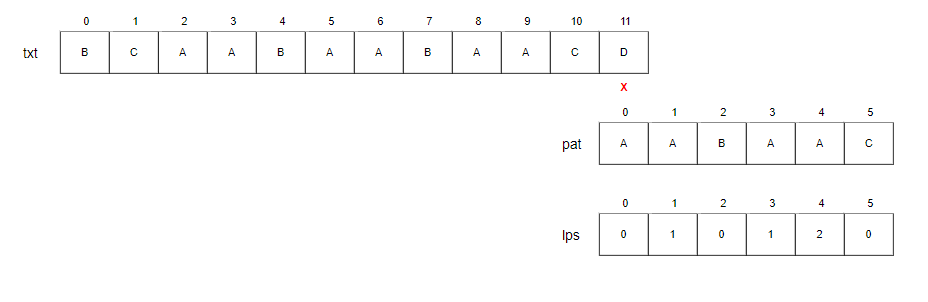
Step15.
- i=12, j=0
- i > N 이므로 모든 txt를 비교했기 때문에 종료합니다.
전처리 단계
lps 배열을 만드는 전처리 단계는 문자열 검색과 비슷한 알고리즘을 사용합니다.
초기화
- len은 패턴 하위 문자열에 대한 proper prefix의 index이면서 lps의 길이이기 때문에 0으로 초기화합니다.
- i는 패턴 하위 문자열에 대한 suffix의 index이기 때문에 1로 초기화합니다.
- 하위 문자열 길이가 1인 경우 proper prefix가 없기 때문에 항상 0입니다. 그렇기 때문에 lps[0] = 0으로 초기화합니다.
lps 배열 구성 작업
match (pat[i] == pat[len])
- pat[i] 와 pat[len]이 일치할 때마다 len을 증가 시킨 뒤, lps[i] = len을 저장하고 i를 증가 시킵니다.
mismatch (pat[i] ≠ txt[j])
- len=0이 아니라면 len을 lps[len-1]에 저장된 값으로 설정합니다.
- len=0이라면 lps[i] = 0으로 설정하고 i를 증가시킵니다.
전처리 단계는 패턴 길이 M만큼 연산을 수행하기 때문에 O(M)이 소요됩니다.
void computeLPSArray(char pat[], int M, int lps[])
{
int len = 0; // lps의 길이 and 패턴 하위 문자열에 대한 proper prefix의 index
int i = 1; // 패턴 하위 문자열에 대한 suffix의 index
lps[0] = 0; // 단일 문자에 대한 proper prefix가 없기 때문에 lps[0]은 항상 0 임.
// lps[] 구성 작업
while (i < M) {
if (pat[i] == pat[len]) // match
{
len++;
lps[i] = len;
i++;
}
else // mismatch (pat[i] != pat[len])
{
if (len != 0)
len = lps[len - 1];
else {
lps[i] = 0;
i++;
}
}
}
}문자열 검색 단계와 동일하기 때문에 그림 예시는 생략하도록 하겠습니다.
성능
pattern의 길이를 M text의 길이를 N이라고 했을 때,
전처리 단계의 시간 복잡도는 \(O(M)\)이고 문자열 검색 단계의 시간복잡도는 \(O(N)\)이기 때문에
KMP 알고리즘의 총 시간 복잡도는 \(O(N+M)\)입니다.



