
머신 러닝으로 시계열(Time Series) 데이터 예측하기
머신 러닝은 시계열 데이터를 예측하는데 자주 사용됩니다.
시계열(Time Series)란?
Time series(시계열)란 일정 시간 간격으로 측정된 데이터의 시퀀스를 말합니다.
시간은 보통 초, 분, 시간, 일, 주, 월, 분기, 연도 등의 단위로 표현되며, 주식 가격, 기온, 수익률, 판매량, 웹 사이트 트래픽 등과 같은 많은 현실 세계의 데이터가 시계열로 표현됩니다.
다음은 책 판매량에 대한 시계열 데이터입니다.
book_sales.head()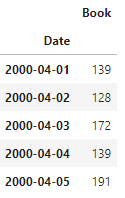
plt.plot(book_sales)
plt.ylabel('Book')
plt.xlabel('Date')
plt.title('Time Plot of Book Sales')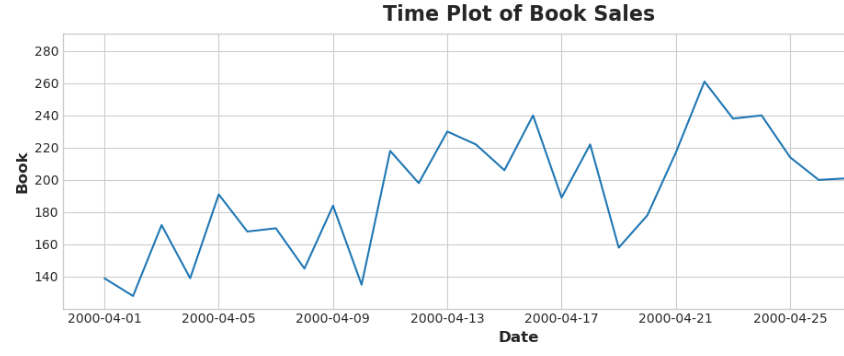
Linear Regression with Time Series
선형 회귀 알고리즘을 사용하여 예측 모델을 구성할 수 있습니다.
선형 회귀는 실제로 널리 사용되는 시계열 예측 알고리즘입니다.
선형 회귀 알고리즘은 주어진 독립 변수(x)에 대한 종속 변수(y)의 값을 예측하고, 예측 값과 실제 값 사이의 차이를 최소화하는 가장 적합한 가중치(=회귀 계수)와 bias(=y 절편)을 찾습니다.
다음은 두 가지 feature에 대한 예입니다.
target = weight_1 * feature_1 + weight_2 * feature_2 + bias
여기서 독립변수(x)는 feature이고 종속변수(y)는 target입니다.
시계열 데이터에는 두 가지 unique feature인 Time-step features와 Lag features가 있습니다.
Time-step features
Time-step features는 시간 인덱스에서 직접 도출할 수 있는 기능입니다.
가장 기본적인 시간 단계 기능은 시리즈의 시간 단계를 처음부터 끝까지 세는 시간 더미입니다.
df = book_sales.copy()
df['Time'] = np.arange(len(df.index))
df.head()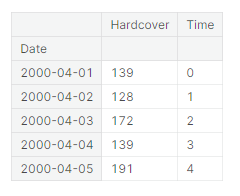
시간 더미를 사용한 선형 회귀는 모델을 생성합니다.
target = weight * time + bias
fig, ax = plt.subplots()
ax.plot('Time', 'Book', data=df, color='0.75')
ax = sns.regplot(x='Time', y='Book', data=df, ci=None, scatter_kws=dict(color='0.25'))
ax.set_title('Time Plot of Book Sales');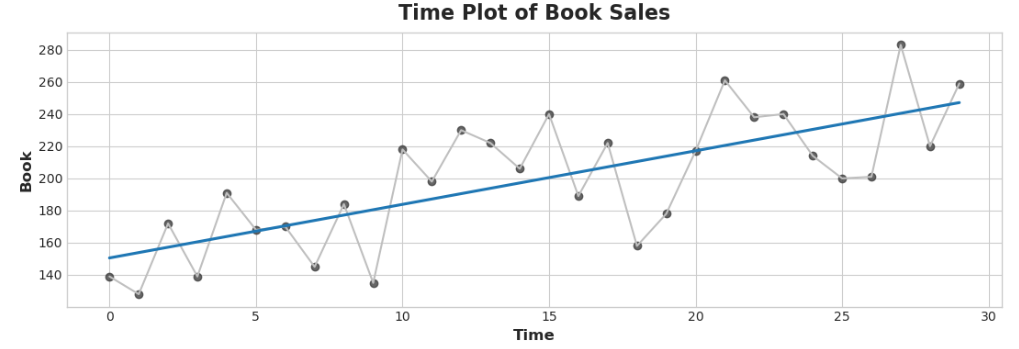
Time-Step features을 사용하면 시간 의존성을 모델링할 수 있습니다.
시간 의존성(Time dependence)
- 시간에 따라 변하거나 시간의 영향을 받는 현상이나 데이터의 속성
시계열은 해당 값이 발생한 시간부터 예측할 수 있는 경우 시간 종속적입니다. 책 판매 데이터에서는 월말의 판매가 일반적으로 월초의 판매보다 높다는 것을 예측할 수 있습니다.
Lag features
Lag features는 target을 이동하여 나중에 발생한 것처럼 보이도록 합니다.
아래 예는 한 단계씩 이동하여 Lag features를 만들었습니다.
df['Lag_1'] = df['Book'].shift(1)
df = df.reindex(columns=['Book', 'Lag_1'])
df.head()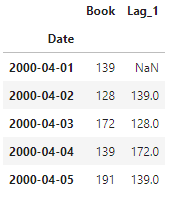
lag feature를 가지고 선형회귀를 합니다.
target = weight * lag + bias
fig, ax = plt.subplots()
ax = sns.regplot(x='Lag_1', y='Book', data=df, ci=None, scatter_kws=dict(color='0.25'))
ax.set_aspect('equal')
ax.set_title('Lag Plot of Book Sales');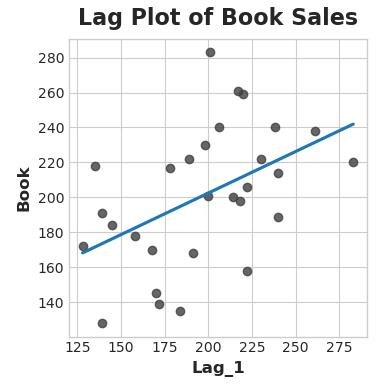
위 표에서 하루의 판매(Book)가 전날의 판매(Lag_1)와 상관관계가 있음을 확인할 수 있습니다.
지연 기능을 사용하면 직렬 종속성을 모델링할 수 있습니다.
직열 종속성(serial dependence)
- 이전 값들이 현재 값에 영향을 미치는 현상
이전 관찰에서 관찰을 예측할 수 있는 경우 시계열에는 직렬 종속성이 있습니다. 책 판매에서 우리는 하루의 높은 판매가 보통 다음 날 높은 판매를 의미한다는 것을 예측할 수 있습니다.
마치며
머신 러닝 알고리즘을 시계열 문제에 적용하는 것은 주로 시간 인덱스 및 시차를 사용한 기능 엔지니어링에 관한 것입니다.

