
판다스(Pandas) 데이터 구조 알아보기
판다스(Pandas)는 python으로 만들어진 데이터 처리 및 분석을 위한 라이브러리입니다.
판다스 데이터 구조를 알아보기 위해선 아래와 같이 모듈을 import 합니다.
import pandas as pd
import numpy as np
데이터 구조
Pandas에서 데이터를 저장하기 위한 객체로 DataFrame과 Series가 있습니다.
DataFrame
Pandas에서는 데이터 테이블을 DataFrame이라고 합니다.
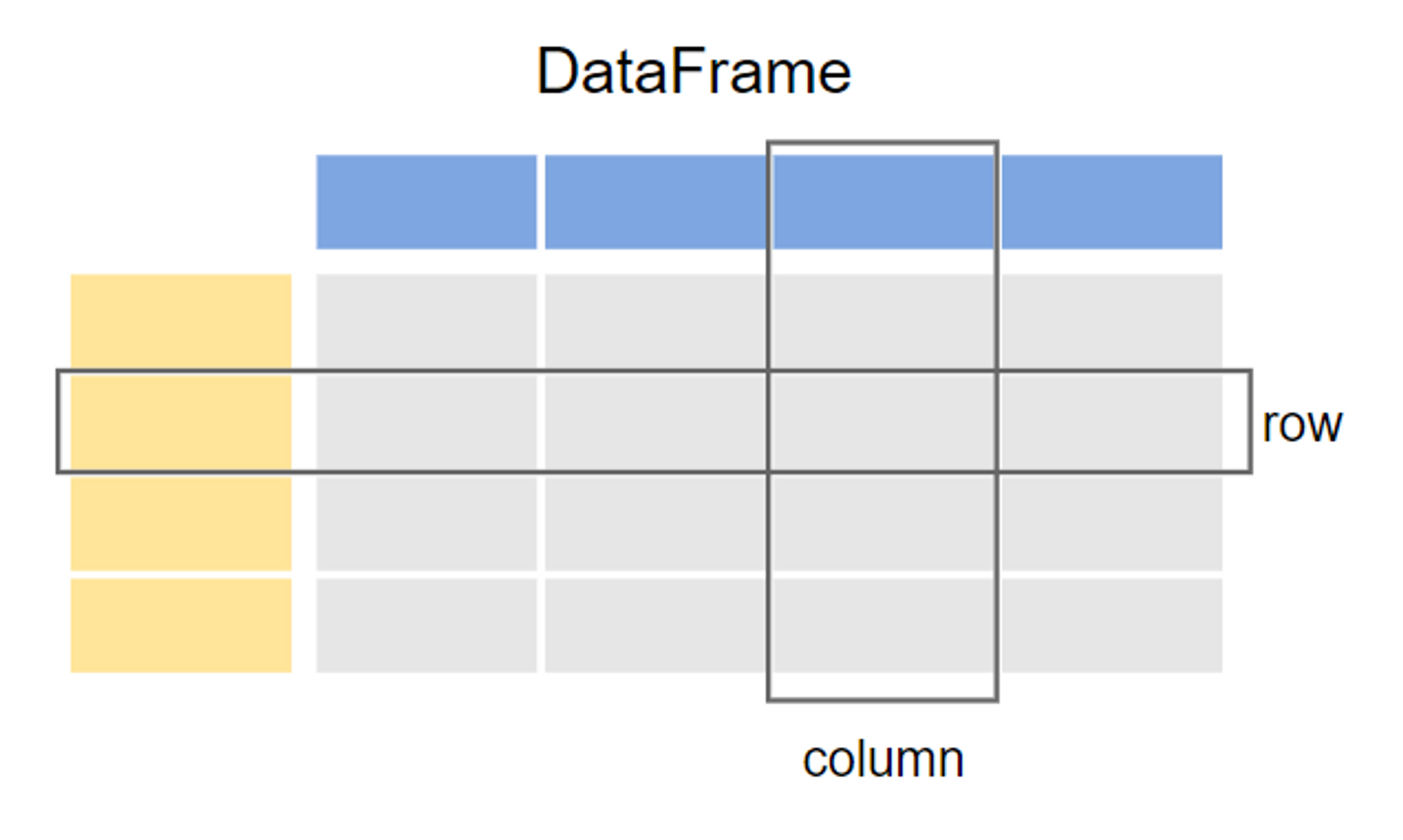
DataFrame은 column label과 row label(=index)를 가지고 있는 2차원 배열 구조입니다.
열에는 다양한 유형의 데이터(문자, 정수, 부동 소수점, 범주형 데이터 등)를 저장할 수 있습니다.
DataFrame을 생성하는 방법은 다음과 같습니다.
dictionary를 이용한 방식
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
df
# output
col1 col2
0 1 3
1 2 4- dict key는 칼럼 header가 되고, 각 list의 값은 DataFrame의 열로 사용됩니다.
- index와 columns를 지정해주지 않으면 0부터 시작하여 1씩 증가하는 인덱스가 사용됩니다.
numpy ndarray를 이용한 방식
d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df2 = pd.DataFrame(data=d, index=[1,2,3], columns=['a', 'b', 'c'])
df2
# output
a b c
1 1 2 3
2 4 5 6
3 7 8 9- 데이터에 ndarray를 사용할 수 있습니다.
- 예제에는 index와 columns도 따로 지정해 주었습니다.
dtypes을 사용하여 각 칼럼의 type을 확인할 수 있습니다.
df.dtypes
# output
col1 int64
col2 int64
dtype: objectdescribe() 메서드를 사용하여 숫자 데이터에 대한 통계를 확인할 수 있습니다.
df2.describe()
# output
a b c
count 3.0 3.0 3.0
mean 4.0 5.0 6.0
std 3.0 3.0 3.0
min 1.0 2.0 3.0
25% 2.5 3.5 4.5
50% 4.0 5.0 6.0
75% 5.5 6.5 7.5
max 7.0 8.0 9.0
728x90
Series
DataFrame의 각 열(column)을 Series라고 합니다.
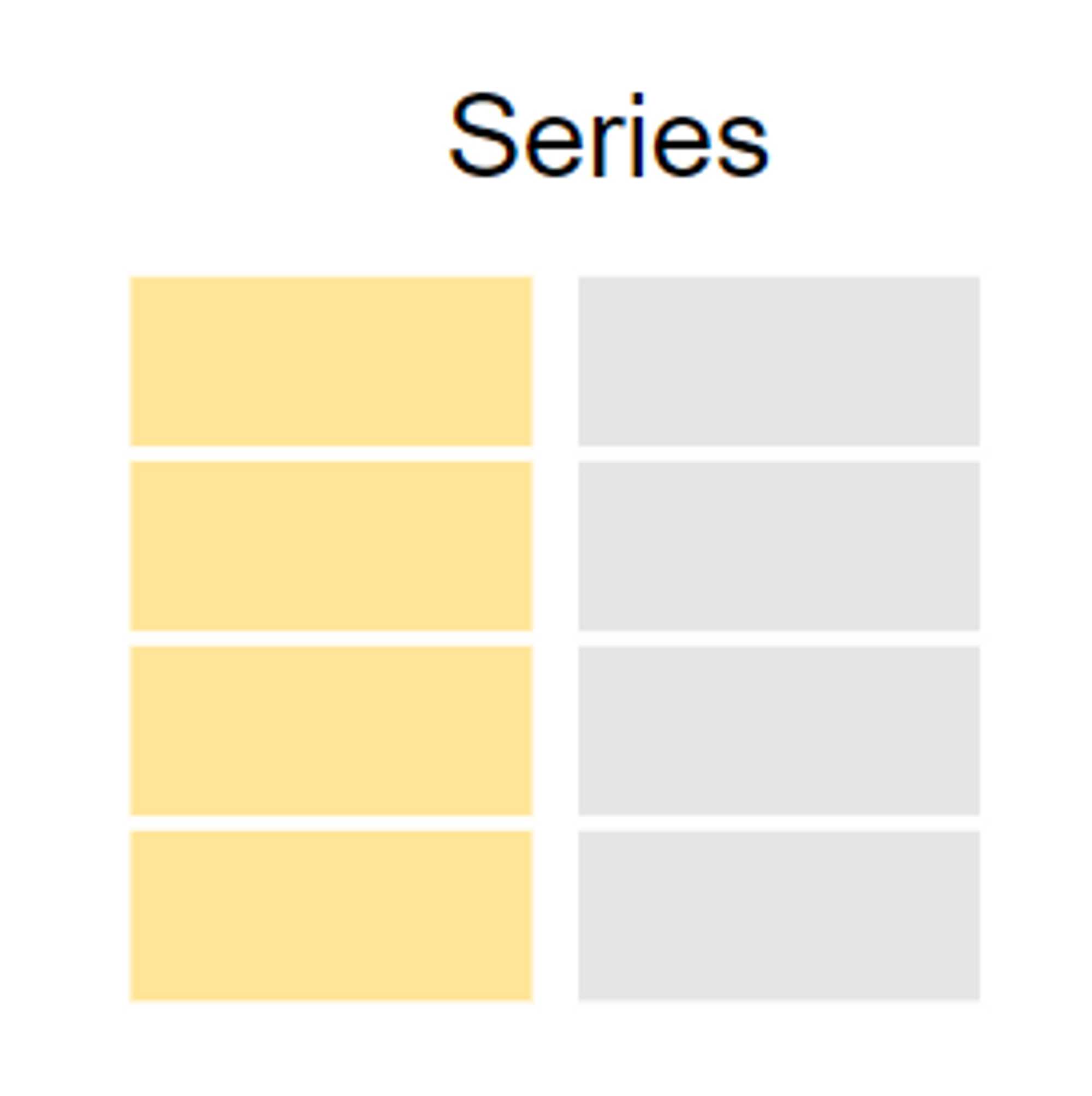
Series는 column label은 없고 row label(=index)만 있는 1차원 배열 구조입니다.
Series를 생성하는 방법은 다음과 같습니다.
DataFrame 조회를 통한 Series 생성
DataFrame에서 단일 칼럼의 조회 결과는 Series입니다.
- 조회하기 위해서는 대괄호([ ]) 사이에 column label을 사용하면 됩니다.
- 다음은 col1 칼럼을 조회하는 예입니다.
df['col1']
# output
0 1
1 2
Name: col1, dtype: int64dictionary를 이용한 방식
d = {"b": 1, "a": 0, "c": 2}
pd.Series(d)
# output
b 1
a 0
c 2
dtype: int64- dict의 key는 Series의 index가 됩니다.
d = {"a": 0.0, "b": 1.0, "c": 2.0}
pd.Series(d)
# output
a 0.0
b 1.0
c 2.0
dtype: float64
pd.Series(d, index=["b", "c", "d", "a"])
# output
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64- index를 사용하면 index 레이블에 해당하는 데이터의 값이 추출됩니다.
- index에 해당하는 값이 없다면 NaN이 들어갑니다. NaN은 누락 데이터(missing data)를 의미합니다.
ndarray를 이용한 방식
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s
# output
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
pd.Series(np.random.randn(5))
# output
0 -0.173215
1 0.119209
2 -1.044236
3 -0.861849
4 -2.104569
dtype: float64- 데이터가 ndarray라면 index와 길이가 같아야 합니다.
- index를 지정해주지 않으면 기본적으로 0부터 시작하여 1씩 증가하는 인덱스가 사용됩니다.
Scalar value를 이용한 방식
pd.Series(5.0, index=["a", "b", "c", "d", "e"])
Out[12]:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64- 데이터가 스칼라 값인 경우 인덱스를 반드시 사용해야 합니다.
- 인덱스 길이만큼 값이 반복됩니다.

