판다스(Pandas) 데이터 선택하기 (Selection)
목차
판다스(Pandas) 데이터 선택하기 (Selection)
Pandas는 DataFrame 또는 Series 개체의 특정 부분을 검색하고 조작할 수 있는 다양한 데이터 선택 방법을 제공합니다.
select를 설명하기 위해 사용하는 DataFrame은 다음과 같습니다.

Selecting Columns
DataFrame에서 열의 하위 집합을 선택하려면 다음 구문을 사용해야 합니다.
df[column_list]
- column_list: 선택하려는 열 이름의 목록
다음은 A행을 가져오는 예입니다.
df['A']
# output
2023-02-18 0.509482
2023-02-19 0.966399
2023-02-20 0.857979
2023-02-21 0.701611
2023-02-22 0.102038
2023-02-23 0.507152
Name: A, dtype: float64

df.A와 결과는 동일합니다. 조회 결과는 Series 객체입니다.
다음은 여러 행을 가져오는 예입니다.
df[['B','D']]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
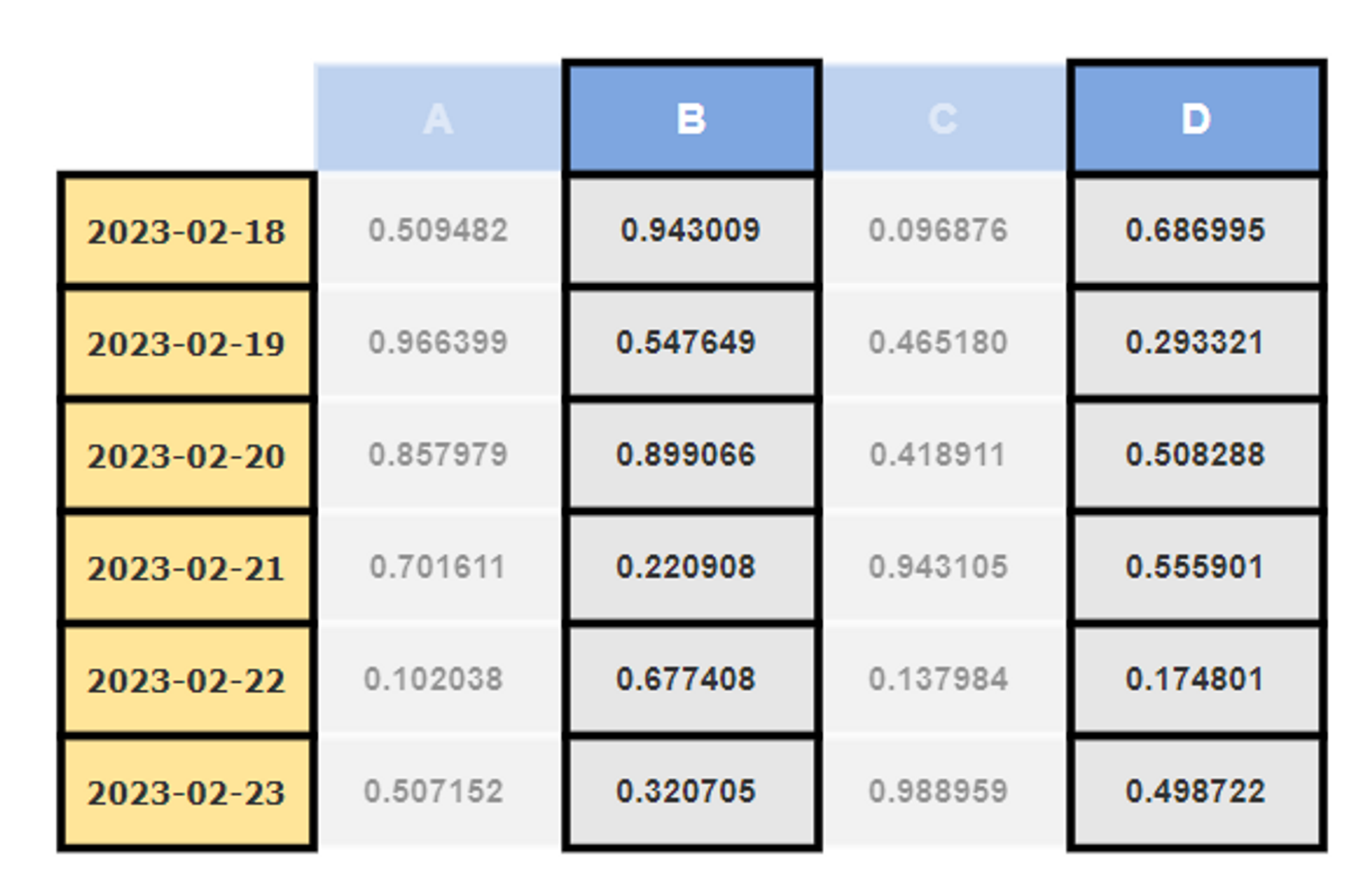
행 리스트를 사용하면 여러 행의 값을 가져올 수 있습니다. 조회 결과는 DataFrame 객체입니다.
Selecting Rows
DataFrame에서 행의 하위 집합을 선택하려면 다음 구문을 사용해야 합니다.
df[start:stop[:step]]
- start: 시작 인덱스
- stop: 종료 인덱스
- step: 요소 사이의 단계 크기, 기본값은 1이다.
종료 인덱스는 선택에 포함되지 않습니다.
다음은 0부터 2번째 행을 가져오는 예입니다.
df[0:3]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
df['2023-02-18':'2023-02-20']
# output
A B C D
2023-02-18 0.509482 0.943009 0.096876 0.686995
2023-02-19 0.966399 0.547649 0.465180 0.293321
2023-02-20 0.857979 0.899066 0.418911 0.508288
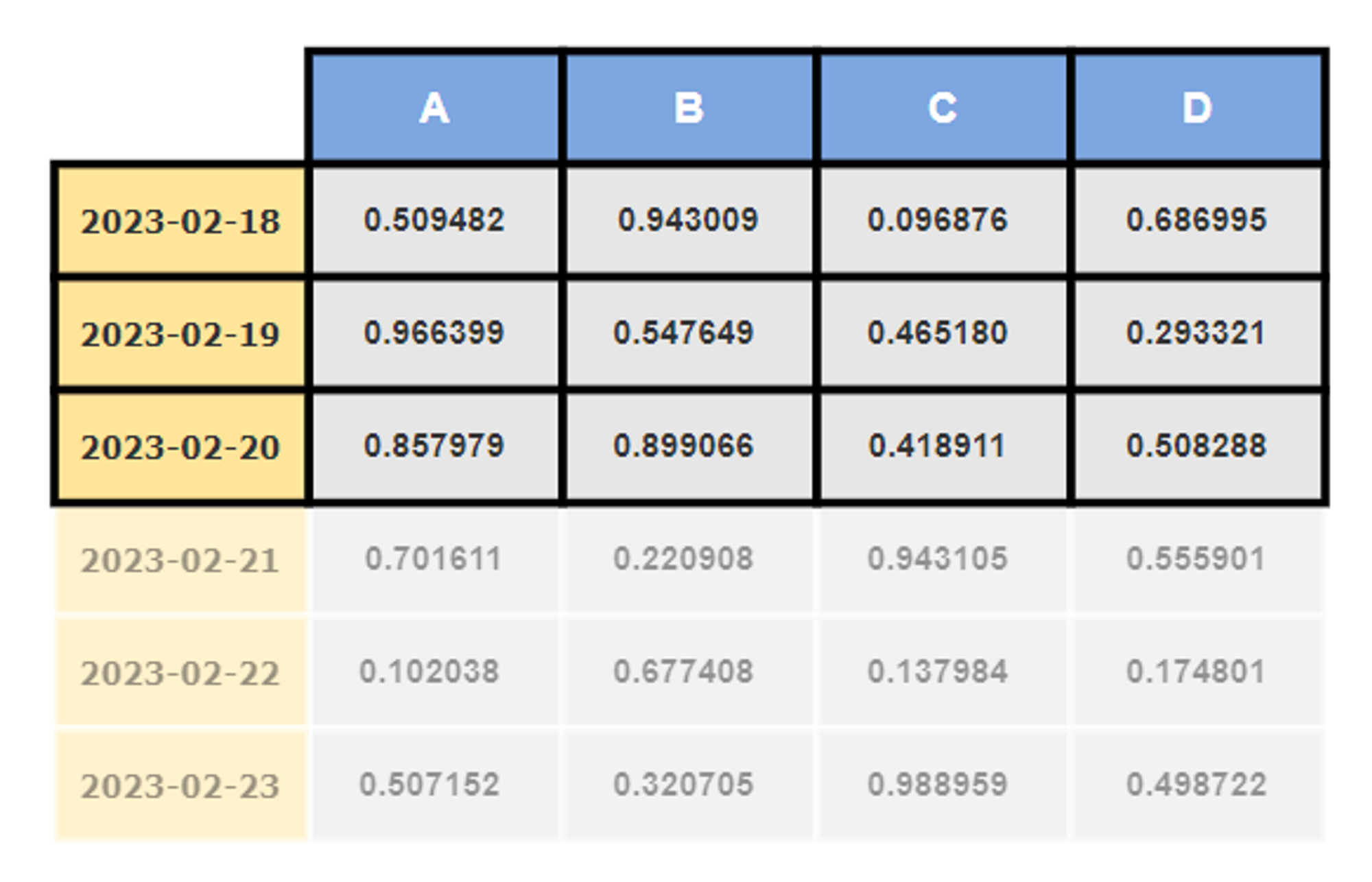
df[0:3:1]과 결과는 동일합니다.
인덱스 대신 인덱스 값을 사용해도 됩니다. df[’2023-02-18’:’2023-02-20’] 이땐 마지막 행도 가져옵니다.
다음은 전체 행에서 2단계식 건너뛰어 행을 가져오는 예입니다.
df[::2]
# output
A B C D
2023-02-18 0.509482 0.943009 0.096876 0.686995
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-22 0.102038 0.677408 0.137984 0.174801
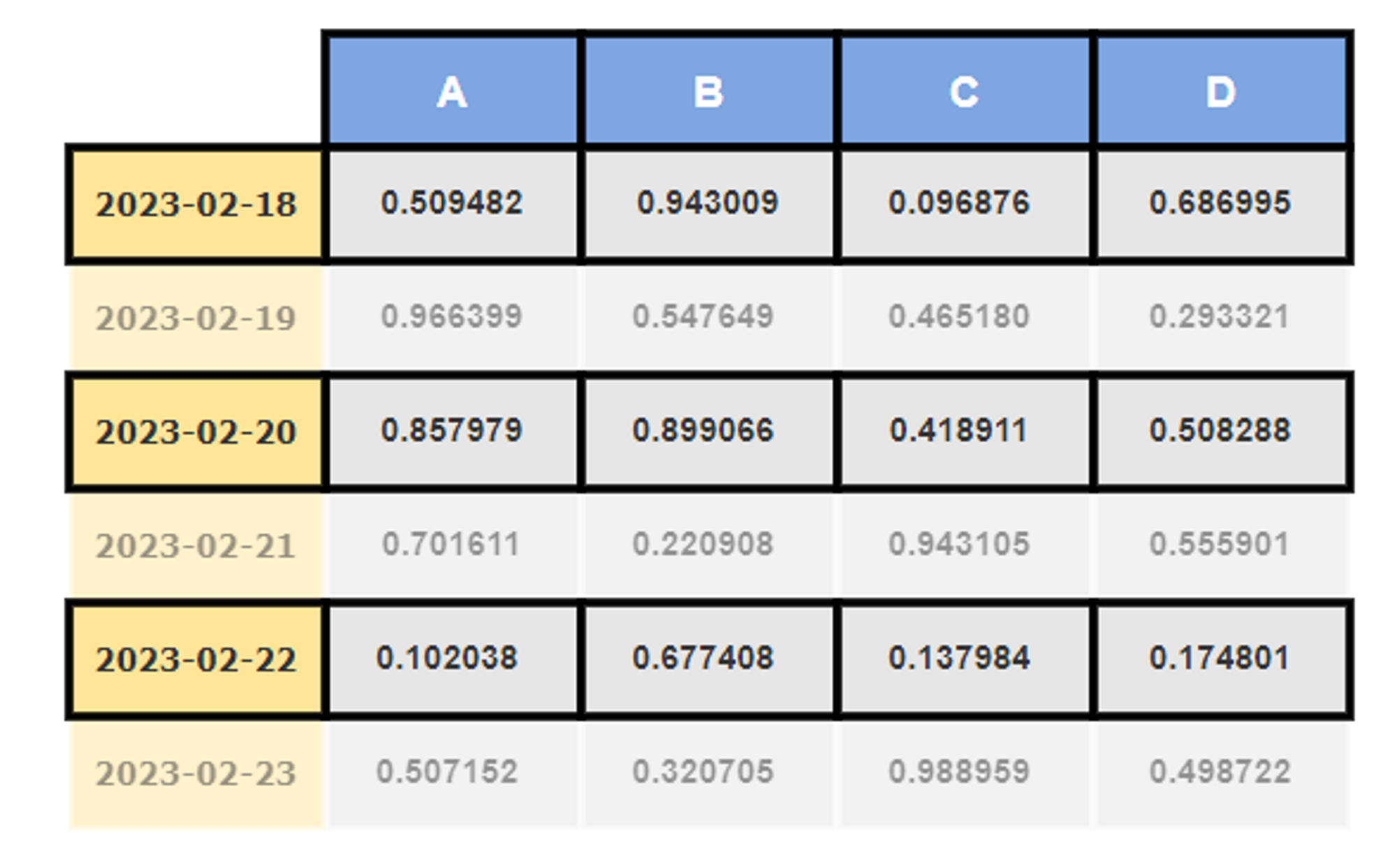
Selection by label
레이블을 이용하여 선택하는 방법은 DataFrame.loc()와 DataFrame.at()이 있습니다.
loc
loc은 행 및 열 레이블로 DataFrame, Series에서 데이터를 선택할 수 있는 레이블 기반 인덱싱 방법입니다.
사용 방법은 다음과 같습니다.
DataFrame
df.loc[row_label [, column_label]]
- row_label: 선택할 행의 레이블
- column_label: 선택할 열의 레이블
시작 레이블과 끝 레이블이 모두 선택 항목에 포함됩니다.
Series
s.loc[index_label]
- index_label: 인덱스 레이블
다음은 loc를 사용하는 여러 가지 예입니다.
행 조회
# 단일 행 조회
df.loc['2023-02-20']
# output
A 0.857979
B 0.899066
C 0.418911
D 0.508288
Name: 2023-02-20 00:00:00, dtype: float64
# slice를 이용한 행 조회
df.loc['2023-02-20':'2023-02-23']
# output
A B C D
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-21 0.701611 0.220908 0.943105 0.555901
2023-02-22 0.102038 0.677408 0.137984 0.174801
2023-02-23 0.507152 0.320705 0.988959 0.498722
# list를 이용한 행 조회
df.loc[['2023-02-20', '2023-02-23']]
# output
A B C D
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-23 0.507152 0.320705 0.988959 0.498722
# boolean을 이용한 행 조회
df.loc[[False, False, True, False, False, True]]
# output
A B C D
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-23 0.507152 0.320705 0.988959 0.498722
열 조회
# 단일 열 조회
df.loc[:,'A']
# output
2023-02-18 0.509482
2023-02-19 0.966399
2023-02-20 0.857979
2023-02-21 0.701611
2023-02-22 0.102038
2023-02-23 0.507152
Name: A, dtype: float64
# slice를 이용한 열 조회
df.loc[:,'A':'C']
A B C
2023-02-18 0.509482 0.943009 0.096876
2023-02-19 0.966399 0.547649 0.465180
2023-02-20 0.857979 0.899066 0.418911
2023-02-21 0.701611 0.220908 0.943105
2023-02-22 0.102038 0.677408 0.137984
2023-02-23 0.507152 0.320705 0.988959
# list를 이용한 열 조회
df.loc[:,['B', 'D']]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
# boolean을 이용한 열 조회
df.loc[:,[False, True, False, True]]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
특정 행과 열 조회
df.loc[['2023-02-20', '2023-02-23'], 'A':'C']
# output
A B C
2023-02-20 0.857979 0.899066 0.418911
2023-02-23 0.507152 0.320705 0.988959
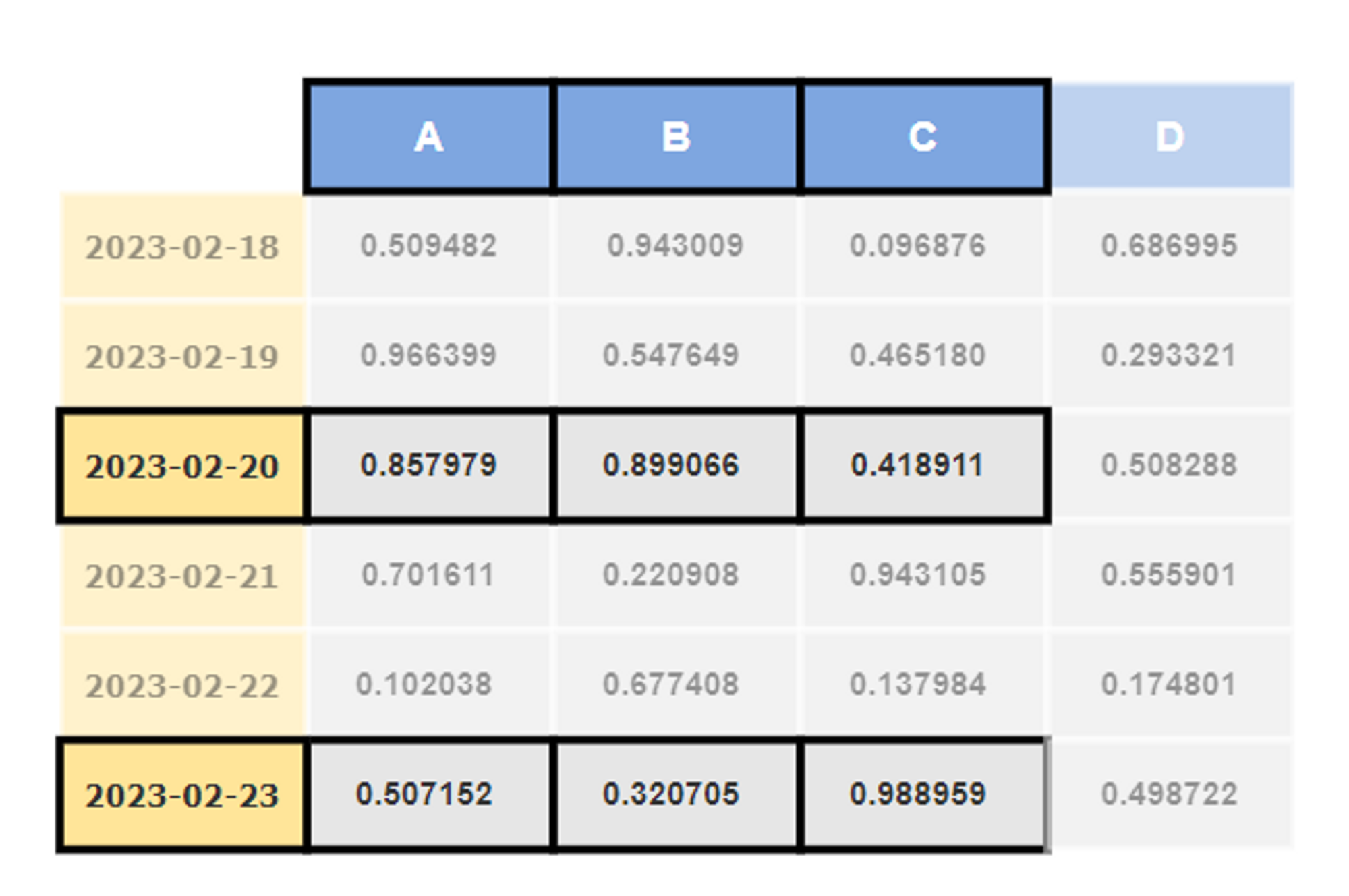
at
at은 행 및 열 레이블에서 DataFrame, Series의 단일 값을 가져옵니다.
at은 단일 값에 특화돼 있어 단일 값 접근 시, loc보다 빠릅니다.
사용 방법은 다음과 같습니다.
DataFrame
df.at[row_label, column_label]
- row_label: 선택할 행의 레이블
- column_label: 선택할 열의 레이블
Series
s.at[index_label]
- index_label: 인덱스 레이블
df.at[df.index[0], 'B']
# output
# 0.943009
s = df.loc[df.index[0]]
s.at['B']
# output
# 0.943009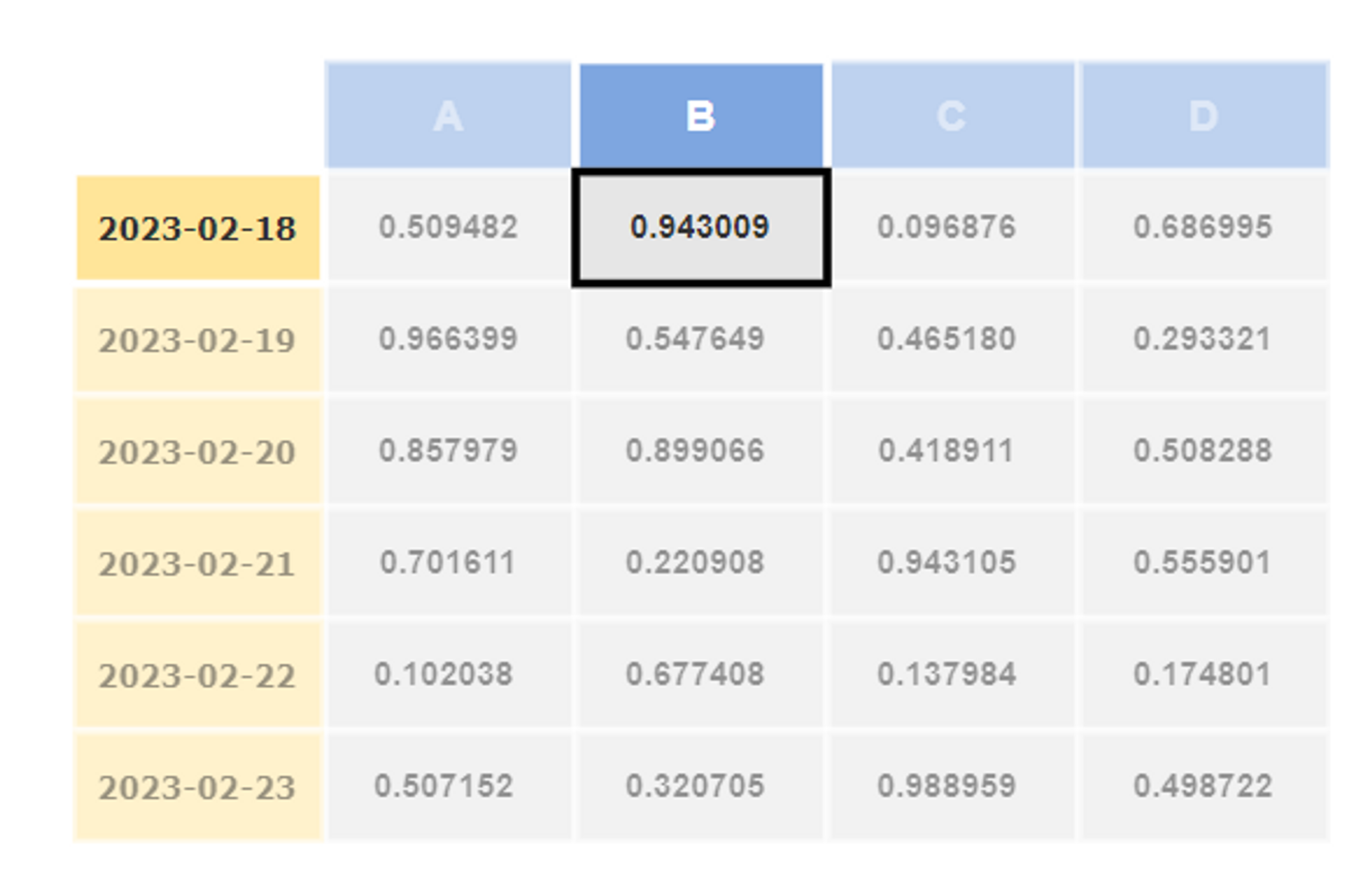
Selection by position
위치를 이용하여 select하는 방법은 DataFrame.iloc()와 DataFrame.iat()이 있습니다.
iloc
iloc은 정수 위치를 기반으로 DataFrame, Series에서 데이터를 선택할 수 있는 인덱싱 방법입니다.
index는 0부터 시작이고 slice에서 마지막 index는 포함되지 않습니다.
사용 방법은 다음과 같습니다.
DataFrame
df.iloc[row_index [, column_index]]
- row_index: 선택할 행의 위치
- column_index: 선택할 열의 위치
Series
s.iloc[index]
- index: Series에서 선택할 요소의 위치
다음은 iloc를 사용하는 여러 가지 예입니다.
행 조회
# 단일 행 조회
df.iloc[0]
# output
A 0.509482
B 0.943009
C 0.096876
D 0.686995
Name: 2023-02-18 00:00:00, dtype: float64
# slice를 이용한 행 조회
df.iloc[:3]
# output
A B C D
2023-02-18 0.509482 0.943009 0.096876 0.686995
2023-02-19 0.966399 0.547649 0.465180 0.293321
2023-02-20 0.857979 0.899066 0.418911 0.508288
# list를 이용한 행 조회
df.iloc[[2, 5]]
# output
A B C D
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-23 0.507152 0.320705 0.988959 0.498722
# boolean을 이용한 행 조회
df.iloc[[False, False, True, False, False, True]]
# output
A B C D
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-23 0.507152 0.320705 0.988959 0.498722
열 조회
# 단일 열 조회
df.iloc[:,0]
# output
2023-02-18 0.509482
2023-02-19 0.966399
2023-02-20 0.857979
2023-02-21 0.701611
2023-02-22 0.102038
2023-02-23 0.507152
Name: A, dtype: float64
# slice를 이용한 열 조회
df.iloc[:, 0:3]
A B C
2023-02-18 0.509482 0.943009 0.096876
2023-02-19 0.966399 0.547649 0.465180
2023-02-20 0.857979 0.899066 0.418911
2023-02-21 0.701611 0.220908 0.943105
2023-02-22 0.102038 0.677408 0.137984
2023-02-23 0.507152 0.320705 0.988959
# list를 이용한 열 조회
df.iloc[:, [1,3]]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
# boolean을 이용한 열 조회
df.iloc[:,[False, True, False, True]]
# output
B D
2023-02-18 0.943009 0.686995
2023-02-19 0.547649 0.293321
2023-02-20 0.899066 0.508288
2023-02-21 0.220908 0.555901
2023-02-22 0.677408 0.174801
2023-02-23 0.320705 0.498722
특정 행과 열 조회
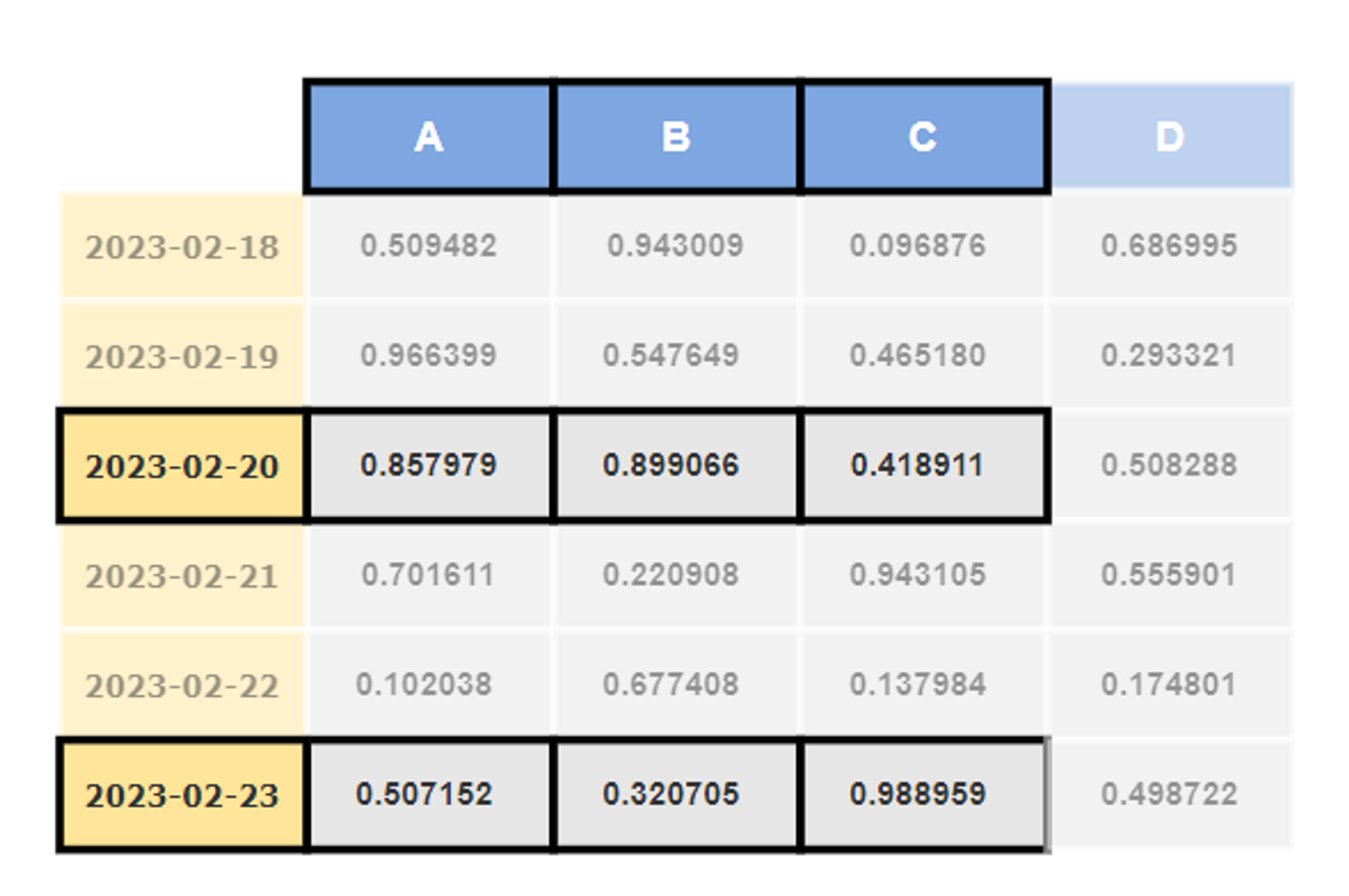
df.iloc[[2, 5], 0:4]
# output
A B C
2023-02-20 0.857979 0.899066 0.418911
2023-02-23 0.507152 0.320705 0.988959
iat
iat은 행 및 열 레이블에서 정수 위치를 기반으로 DataFrame, Series의 단일 값을 가져옵니다.
iat은 단일 값에 특화돼 있어 단일 값 접근 시, iloc보다 빠릅니다.
index는 0부터 시작입니다.
사용 방법은 다음과 같습니다.
DataFrame
df.iat[row_index, column_index]
- row_index: 선택할 행의 위치
- column_index: 선택할 열의 위치
Series
s.iat[index]
- index: Series에서 선택할 요소의 위치
df.iat[0, 1]
# output
# 0.943009
s = df.loc[df.index[0]]
s.iat[1]
# output
# 0.943009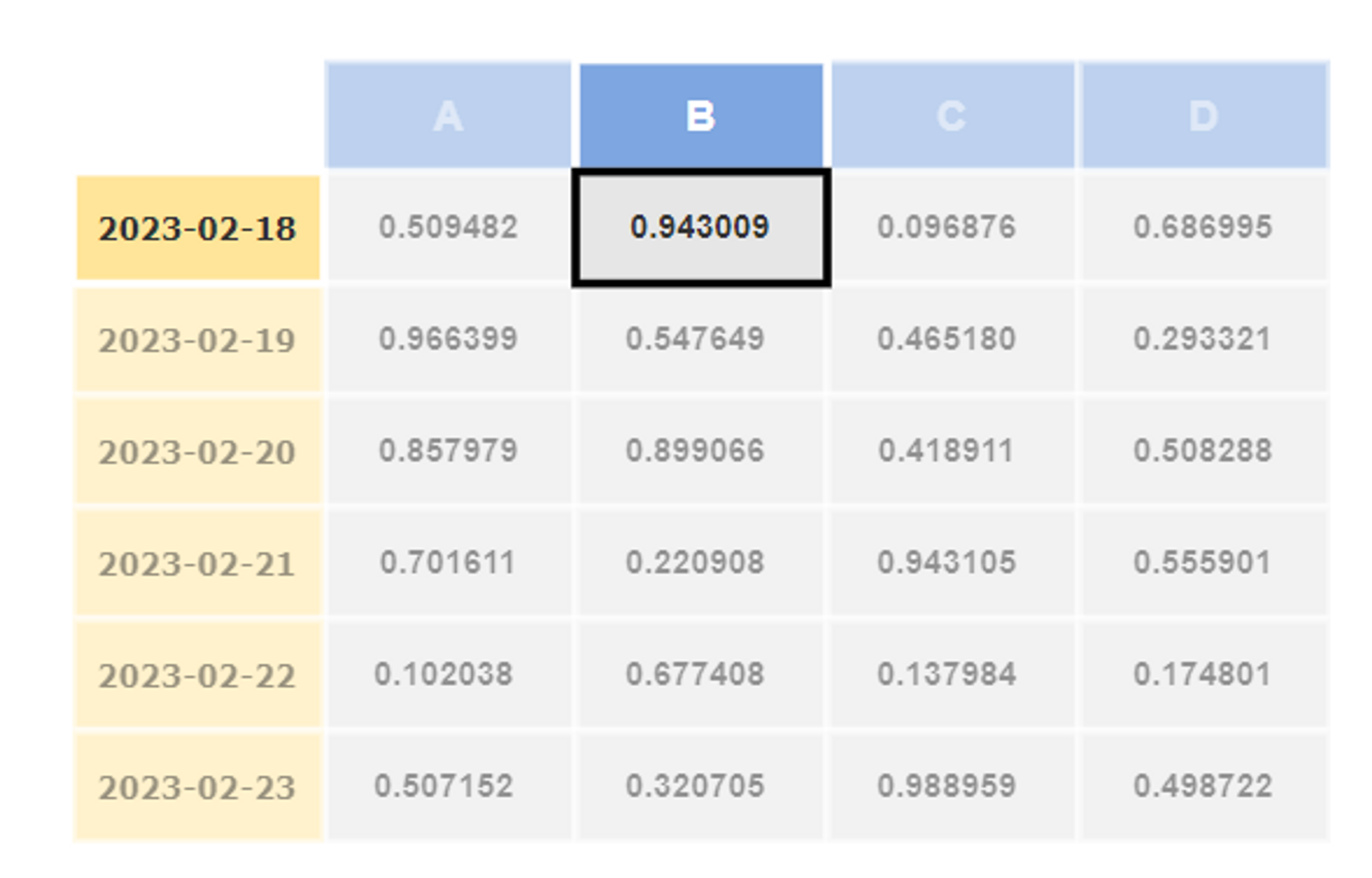
Boolean indexing
Boolean indexing은 boolean 조건을 사용하여 DataFrame, Series에서 데이터를 선택하는 방법입니다.
boolean 조건은 비교 연산자, 논리 연산자를 사용해서 만듭니다.
비교 연산자
- ‘==’, ‘≠’, ‘<’, ‘>’, ‘≤’, ‘≥’
논리 연산자
- ‘&’ (and), ‘|’ (or)
다음은 Boolean indexing 예입니다.
# 단일 열의 값을 사용하여 데이터 선택
cond = df['A'] > 0.7
df[cond]
# output
A B C D
2023-02-19 0.966399 0.547649 0.465180 0.293321
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-21 0.701611 0.220908 0.943105 0.555901
# DataFrame에서 값 선택
cond = df > 0.7
df[cond]
# output
A B C D
2023-02-18 NaN 0.943009 NaN NaN
2023-02-19 0.966399 NaN NaN NaN
2023-02-20 0.857979 0.899066 NaN NaN
2023-02-21 0.701611 NaN 0.943105 NaN
2023-02-22 NaN NaN NaN NaN
2023-02-23 NaN NaN 0.988959 NaN
# 논리연산자를 사용하여 값 선택
cond = (df['A'] > 0.7) & (df['A'] < 0.8)
df[cond]
# output
A B C D
2023-02-21 0.701611 0.220908 0.943105 0.555901
cond = (df['A'] > 0.7) | (df['C'] < 0.5)
df[cond]
# output
A B C D
2023-02-18 0.509482 0.943009 0.096876 0.686995
2023-02-19 0.966399 0.547649 0.465180 0.293321
2023-02-20 0.857979 0.899066 0.418911 0.508288
2023-02-21 0.701611 0.220908 0.943105 0.555901
2023-02-22 0.102038 0.677408 0.137984 0.174801