
Raft Consensus Algorithm 알아보기
Raft는 이해하기 쉽도록 설계된 분산 합의 알고리즘입니다.
여러 서버들 중 일부 서버에 장애가 발생하더라도 기능을 유지하도록 하는 내결함성을 가지고 있습니다.
분산 합의(Distributed Consensus)란?
하나의 클라이언트와 서버가 있고 클라이언트가 서버에게 데이터를 전달한다고 가정해보겠습니다. 서버는 하나의 노드로 이루어져 있기 때문에 합의가 이루어지는 건 아주 쉬운 문제입니다.

여기서 합의란 클라이언트와 서버가 동일한 데이터를 공유하는 상태(동기화)가 되는 것을 의미합니다.
만일 위 그림처럼 여러 노드로 이루어진 분산 서버에서 합의를 할 때 발생하는 문제를 distributed consensus problem이라고 합니다.
Raft 작동방식
Raft상에서 서버 노드는 세 가지 상태 중 하나를 가지게 됩니다.
- Follower state - leader로부터 AppendEntry메시지를 받아 처리하는 상태입니다. 일정 시간이 이상 AppendEntry 메시지를 받지 못하면 상태를 cadidate로 변경합니다.
- Candidate state - leader로 선출될 수 있는 후보군으로 Candidate 노드는 투표 요청 메시지(Vote request)를 다른 노드에 보내서 과반수 이상의 노드들로부터 투표를 받게 되면 새로운 리더가 됩니다.
- Leader state - leader로 선출된 상태, 변경 내역은 leader를 통해서만 follower에게 전달하여 반영합니다. 어느 시점에서든 최대 하나의 리더만 있을 수 있습니다.
- 아래 그림은 서버 노드의 상태 전환 flow입니다.
Term
Term은 Leader 선출 시에 할당되는 1씩 증가하는 Sequence번호로써 Leader에 ID역할을 합니다.
Term은 Leader가 변경 될 때까지 유지되고 서버 간의 통신 중에 전달됩니다.
Term은 리더 선출(leader election) 때 투표의 중복을 피하기 위해 사용됩니다.
Term은 다음과 같은 작업을 수행합니다.
- Term이 다른 서버의 term보다 작은 경우 서버는 term을 업데이트합니다.
- Candidate 또는 Leader의 term이 다른 노드보다 작다면 Follower로 됩니다.
- 오래된 term으로 요청이 오면 해당 요청은 거부됩니다.
프로토콜
Raft는 두 가지 유형의 RPC 프로토콜을 사용합니다.
- RequestVotes - Candidate 노드에 의해 전달되고 선거기간 동안 투표를 얻기 위해 사용됩니다.
- AppendEntries - Leader 노드에 의해 전달되고 로그 항목을 복제하기 위해 사용되거나 하트비트 메커니즘으로도 사용됩니다. (하트비트 메커니즘으로 사용될 땐 빈 AppendEntries를 사용합니다.)
리더 선출(leader election)
리더 선출 과정은 다음과 같습니다.
- 모든 노드는 follower 상태에서 시작합니다. election timeout 후 follower가 candidate가 되어 새로운 선거 기간(Term)을 시작합니다.
- election timeout - 팔로워가 후보자가 될 때까지 기다리는 시간입니다. (150ms~ 300ms사이로 무작위로 지정됨)
- Candidate 노드는 자신에게 투표하고 RequestVotes RPC를 follower에게 보냅니다.
- Follower가 현재 term내에 투표한 적이 없다면 곧바로 투표 요청을 Candidate에게 응답(Vote)을 합니다.
- 모든 노드는 term당 한번의 투표만 할 수 있습니다.
- 응답을 한 Follower는 election timeout을 초기화합니다.
- 과반수 이상의 투표를 받은 Candidate는 Leader가 됩니다.
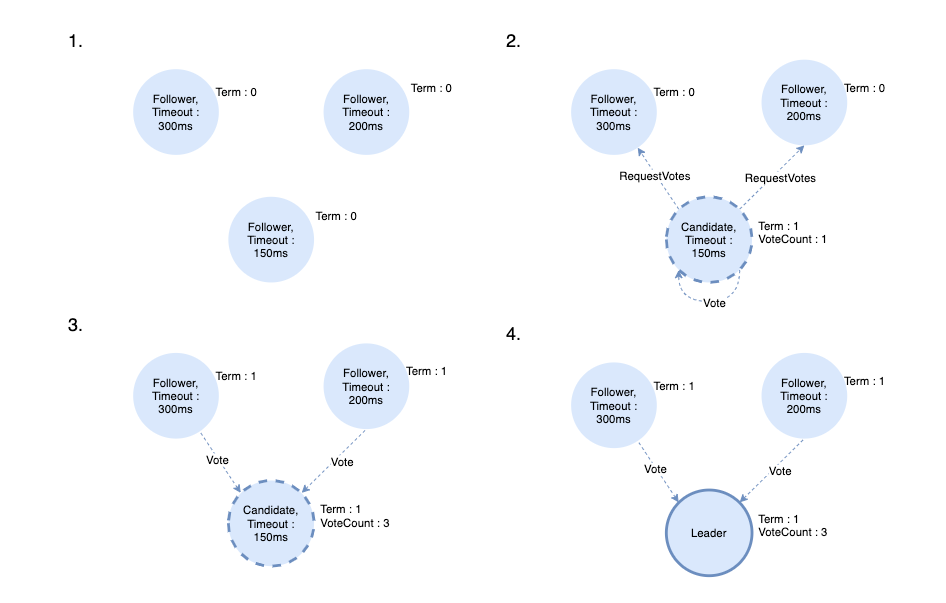
리더 선출 후, Leader는 Follower에게 AppendEntries 메시지를 보내기 시작합니다.
이러한 메시지는 Heartbeat timeout 에 지정된 간격으로 전송됩니다.
Follower는 election timeout을 초기화하고 각 AppendEntries 메시지에 응답합니다.
이 선거 기간(Term)은 Follower가 Heartbeat 수신을 중단하고 Candidate가 될 때까지 계속됩니다.
리더 선출 과정에는 여러 가지 상황이 있을 수 있습니다.
re-election 상황
재 선거 과정은 다음과 같습니다.
- Leader 노드가 죽어 더 이상 AppendEntries메시지 보내지 못합니다. election timeout 후 Follower가 Candidate가 되어 새로운 선거 기간(Term)을 시작합니다.
- Candidate 노드는 자신에게 투표하고 RequestVotes RPC를 Follower에게 보냅니다.
- Follower가 현재 term내에 투표한 적이 없다면 곧바로 투표 요청을 Candidate에게 응답(Vote)을 합니다.
- 과반수 이상의 투표를 받은 candidate는 leader가 됩니다.
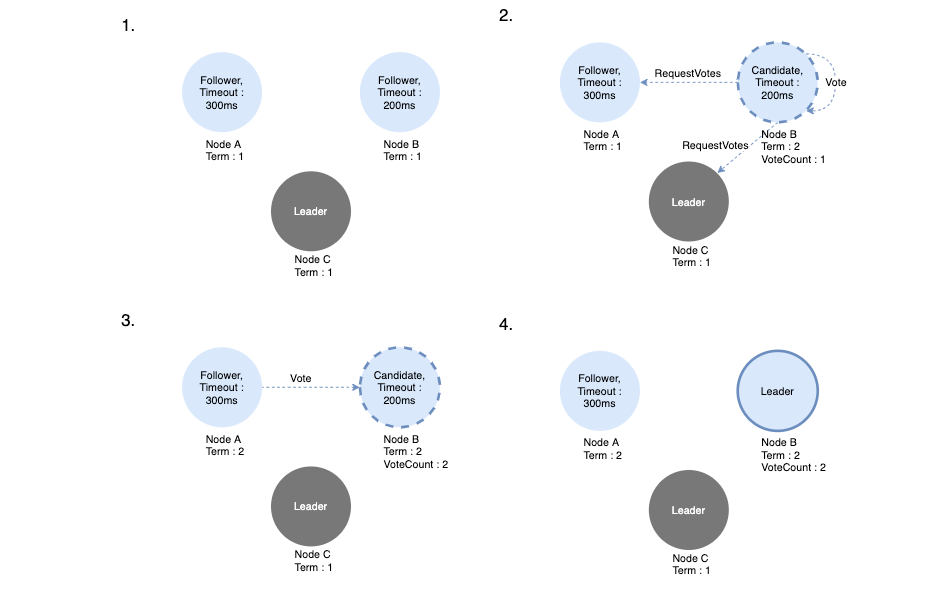
Term 당 하나의 Leader만 선출될 수 있습니다.
두 노드가 동시에 Candidate가 되는 상황
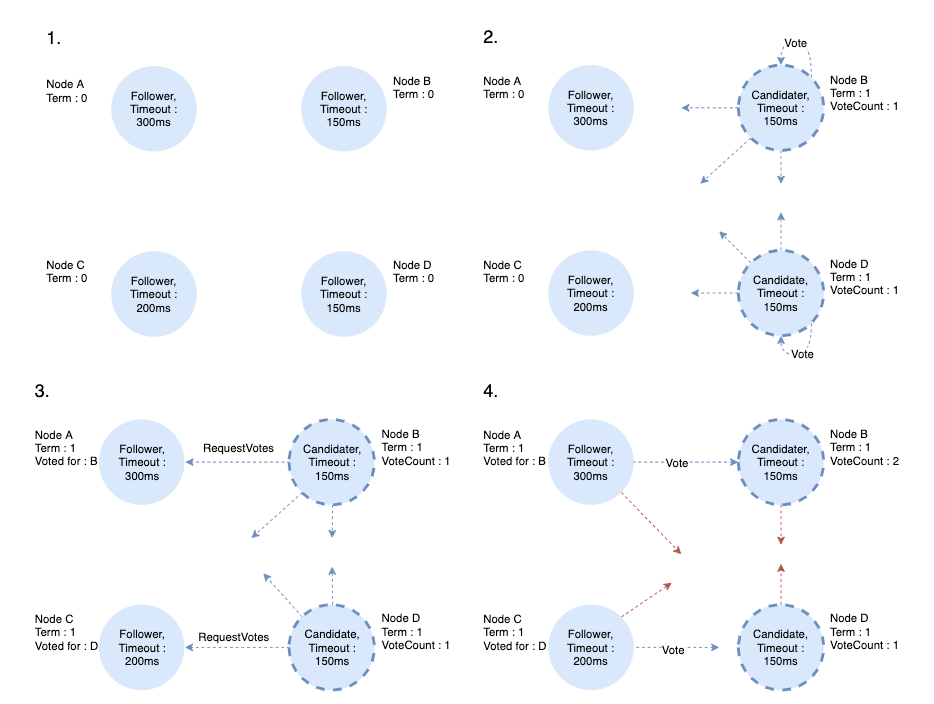
두 노드가 동시에 Candidate가 되는 경우 다음과 같은 과정을 거칩니다.
- election timeout 후 동시에 두 개의 Follower가 Candidate가 되어 새로운 선거 기간(Term)을 시작합니다
- Candidate 노드 각각은 자신에게 투표하고 RequestVotes RPC를 각 노드에 보냅니다.
- Candidate 노드 각각은 다른 하나보다 먼저 단일 Follower 노드에 도달합니다.
- Follower가 현재 term내에 투표한 적이 없다면 곧바로 투표 요청을 Candidate에게 응답(Vote)을 합니다.
- 노드는 term 당 한 번만 투표(Vote) 할 수 있습니다.
- 과반수를 얻지 못해 Leader를 선출하지 못했다면 election timeout 후 다시 새로운 선거 기간(Term)을 시작합니다.
- 이번에는 하나의 노드만 Candidate가 되어 투표를 진행합니다.
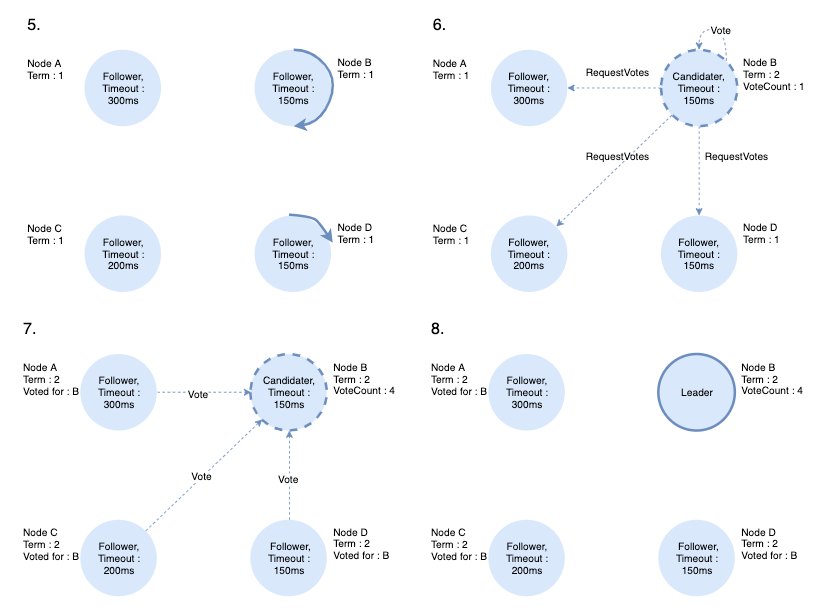
- 이전 선거에서 Candidate였던 노드 D는 더 높은 Term의 RequestVotes 메시지를 받았기 때문에 Follower로 상태를 변경하고 Candidate에게 응답(Vote)을 합니다.
- 과반수 이상의 투표를 받은 candidate는 leader가 됩니다.
Leader election은 하나의 Leader를 선출할 때까지 1~4를 계속 반복하게 됩니다.
로그 복제(log replication)
이제 시스템에 대한 모든 변경 사항이 Leader를 통하게 됩니다.
각 변경 사항은 노드의 로그 엔트리(Log Entries)에 추가되고 다른 노드(Follower)에 복제됩니다.
이는 AppendEntry 메시지를 사용하여 수행됩니다.
Leader는 Heartbeat timeout 주기마다 한 번씩 AppendEntries 메시지를 Follower에게 전달합니다.
일반적으로 로그 엔트리는 다음 세 가지 정보가 포함됩니다.
- Term - Leader 선출 시에 할당되는 1씩 증가하는 Sequence 번호
- Index - Log가 저장될 때마다 1씩 증가하는 Sequence 번호 (인덱스는 1부터 시작함)
- Data
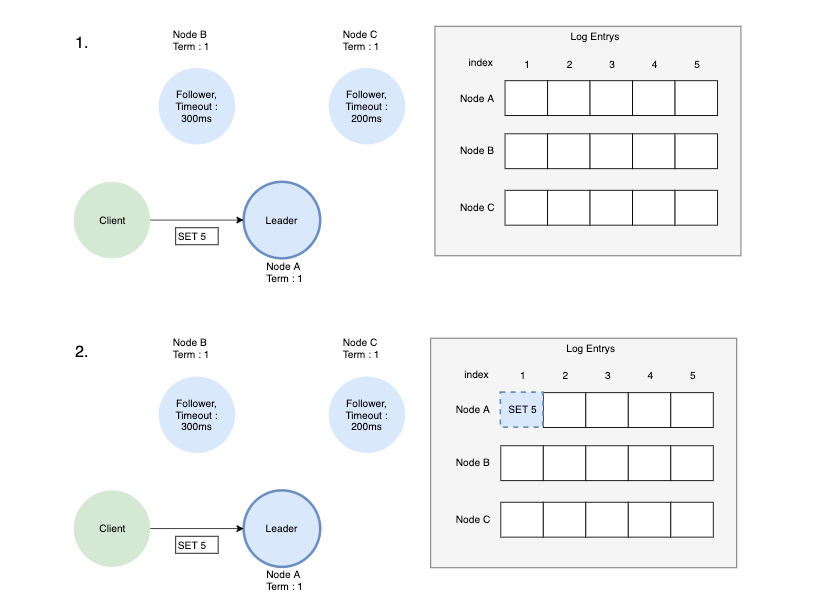
로그 복제과정은 다음과 같습니다.
- 먼저 클라이언트가 Leader에게 변경 사항을 보냅니다.
- 변경 사항은 Leader의 Log Entry에 저장됩니다.
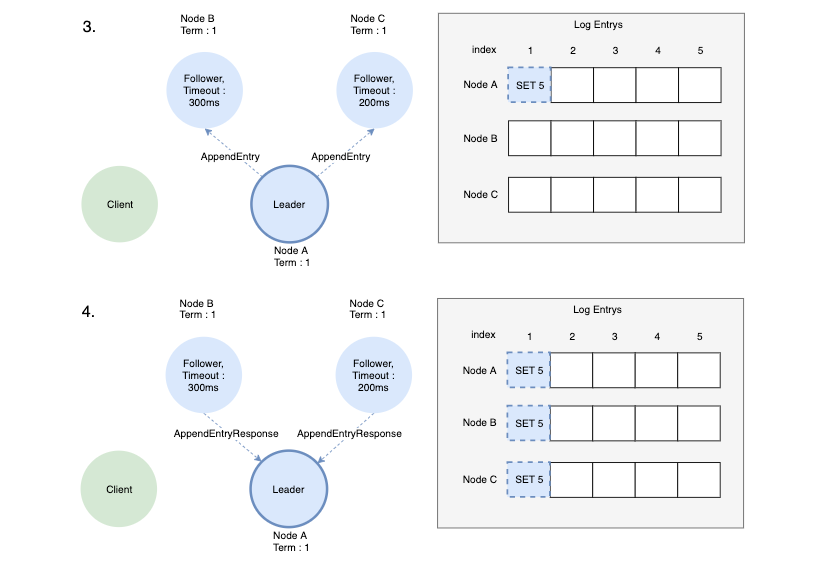
- Leader는 다음 heartbeat에 log를 AppendEntry 메시지 형태로 Follower에게 전달합니다.
- AppendEntry메시지를 받은 Follower는 새로운 Log entry를 저장하고 AppendEntryResponse메시지로 성공 응답을 보냅니다.
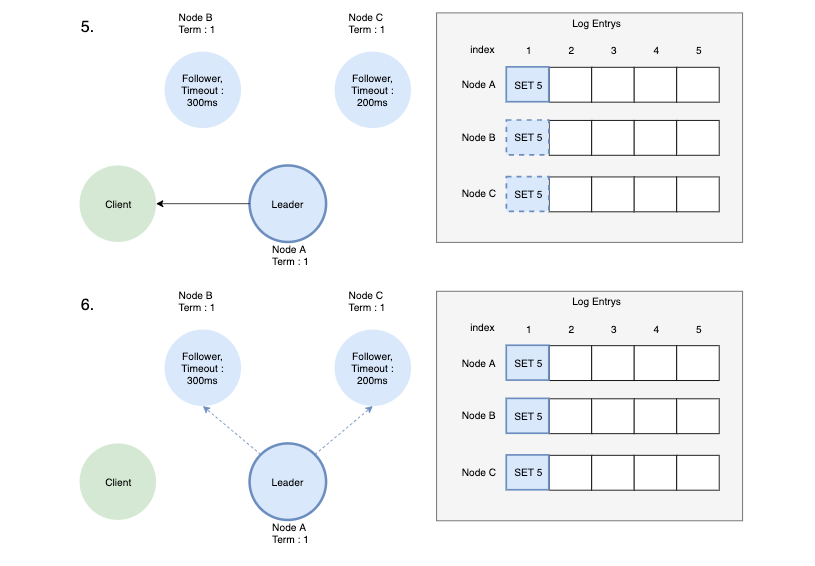
- 과반수 응답을 받았다면 Leader는 자신의 entry를 commit 하고 Client에게 응답 메시지를 보냅니다.
- 그리고 Follower들에게도 변경 사항이 commit 되었음을 알리고 알림을 받은 Follower들은 커밋을 합니다.
참고:



